A toolset to make scientific computer simulations easier to run, manage and evaluate. I write more about it here.
The more I think about it, the more I believe that the links I bookmark everyday are an important dimension of my online life. They're mine to keep.
When Google Reader »integrated« several of its Reader's features into GooglePlus, my friend Jan and me made the switch to a self-hosted RSS Reader (tiny, tiny rss, I talked about the switch here).
It is an awesome product to manage incoming RSS content for personal reading. It also gives you the possibility to publish/share an outgoing RSS stream with the best articles from what came in.
However, we still missed the possibility to put any page we read on the web into the outgoing RSS stream. Also, Google Reader had a nicer widget to put the outgoing stream on a personal website. And finally, Google still had all our shared data. I have, with Jans help, solved all of these three concerns with a straightforward add-on to tiny, tiny rss (we call it gritttt-rss). It is all described in more detail on a dedicated website, with even a picture with arrows and everything:
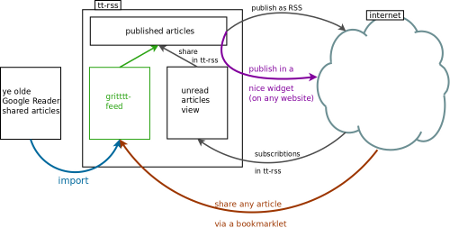
The little widget in the right lower corner on this website now shows my "shared" outgoing RSS stream in the widget I made.
Why did I go to so much trouble? While doing this challenging project (it actually included solving many small web development challenges and was much fun, as well), I realised why:
It is not so much about sharing links, not in the first place, that is. I myself want to keep bookmarks of what I read each day. I believe that the links I bookmark everyday are an important dimension of my online life. I bookmark a couple links everyday, and years later I can look back and understand what I was interested in during certain times.
Unlike online services like Delicious or Pinboard, however, I host the list of bookmarked links myself - I really own that data. And the method (the gritttt-rss code) is open-source.
A Content Management System I wrote recently (and on which this site is running on).
You will find more here.
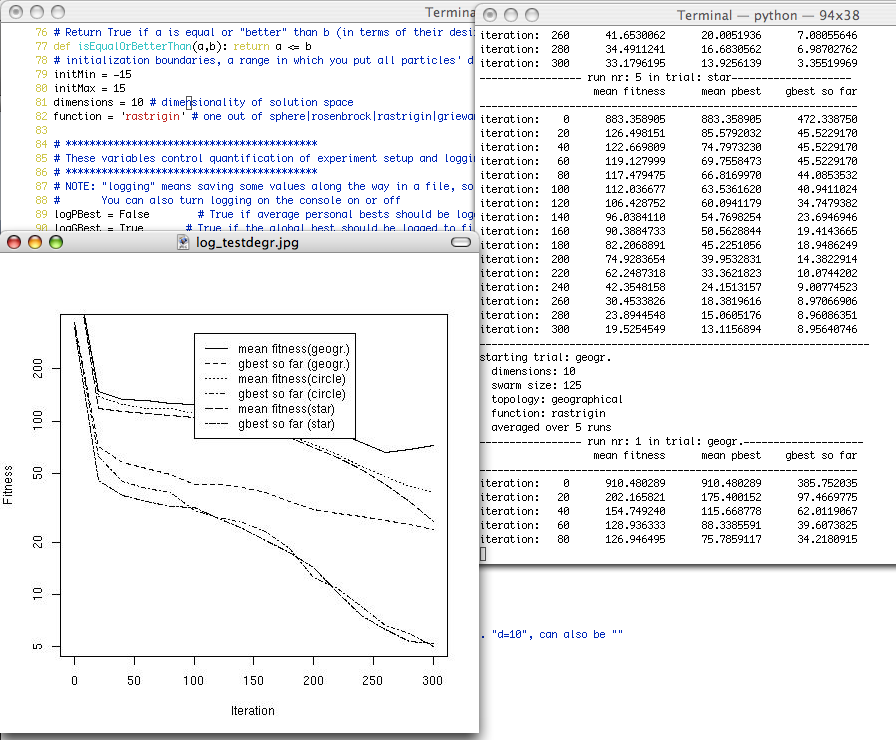
Here is a basic list of features to play with. For example:
- Several topologies (circle, star and geographical neighborhood)
- Some standard functions to test on (sphere,griewank,rastrigin,rosenbrock)
- Logging capabilities (to csv format, even code to plot graphs with that data in GNU R can be produced)
- Experiment setups. Average over many iterations and/or automatically change conditions of your choice and let several trials run while you get a fresh cup of coffee :-)
To use it, open a Python session and type:
$ import pso
$ pso.run()
I have the code over at Google Code.
Here are the slides of my tutorial sessions that deal with general topics rather than with what to do for the next homework:
- Tutorial 1 - Debugging Prolog (84 kB)
- Tutorial 2 - Induction and Recursion, Lists, Unification (382 kB)
- Tutorial 3 - Base Cases, The Fruits of Left Recursion, Accumulator (460 kB) and some code: gauss.pro
- Tutorial 4 - Translating Natural Language to First Order Logic and that to Prolog
- Tutorial 8 - A toy natural language system using prolog (85 KB)
- Tutorial 9 - The Cut Operator (60 KB)
At University College, Dublin, I took the excellent course "Natural Programming" by Dr. Michael O'Neill. A part of it was to write your own paper and let the other students review it.
As a topic, I chose Particle Swarm Optimization. I was interested in defining the neighbourhood of particles geographically, which is how swarms in nature act. The standard algorithms mostly use fixed neighbourhood relations.
It was received very well and so I present it here for you to view/download.
I'll leave you with the abstract:
In Particle Swarm Optimization (PSO) with local neighbourhood, the social part of change in the particle's velocity is computed considering the performance of a set of neighbours. Almost all of the literature uses neighbourhood relations of a fixed topology. This paper introduces a method that computes a local optimum based on geographical, non- fixed neighbourhood in Euclidian space. It compares the two approaches in performance and geographical behaviour. The results show that swarms with geographical neighbourhood perform worse in terms of fitness. Furthermore, the results indicate that swarms with fixed topologies start by exploring the search space due to initial random distribution and then turn to exploitation because of emerged geographical neighbourhood.
I also published the code I used for the simulations.
I came up with this little tool before christmas 2005 to make my girl happy :-)
basically, this is just an advent calendar that works with PHP and JavaScript. When you open index.html, 24 doors will "fly" over the screen, each to its location.
 If you click on a door, a little window opens and displays the text it finds for that day in the database (the SQL-insert is also here).
If you click on a door, a little window opens and displays the text it finds for that day in the database (the SQL-insert is also here).
Of course I know that the design is somehow ugly. Heck, the code even makes up the colors by random (but still cares for contrast). That resembles my weird sense of humor. sorry.
To run this four yourself, you need:
-a web host server that supports PHP 4.x or higher
-a MySQL database
The rest is said in readme.txt. Setting this up is no big deal if you know how to deal with a MySQL database (setup a table from an SQL script).
During the "philosophy of mind" - course, I had to write six essays about the texts we were reading once a week. That taught me a lot respect about analytical thinking, I tell you. It's not easy to put so much thought in two pages, but I tried my best :-)
Among these are the first proposals for important aspects of Artificial Intelligence and, as important, sketches of problems that it faces!
- Hilary Putnam – The nature of mental states (1967)
- Daniel Dennett - Intentional Systems (1979)
- Saul Kripke – The Identity Thesis / Excerpt from “Identity
and Necessity” (1980/1971) - John Haugeland – Semantic Engines: An Introduction to Mind Design (1981)
- Paul Churchland – Eliminative Materialism and the Propositional
Attitudes (1981) - Thomas Nagel – How is it like to be a bat? (1981)
For more information, see the comments on the code...
While giving your site some personal touch, you might wish to have hover-over-popups that describe to the user what he should expect to find behind that link he is interested in.
While there is a standard way to do that (<a title="Hit this!">a link</a>), you might want to
- make the popups come up directly without delaying 2 seconds or so because the user wants to know what is behind that link immediately
- style those popups your own way, not that peculiar yellow the browsers use for that... and you want to do it the CSS way.
- Heisele et al: 'Face Recognition With Support Vector Machines: Global versus Component-Based Approach', Center for Biological and Computational Learning Cambridge, 2001
- Romdhani et al: 'Computationally Efficient Face Detection', Microsoft Research Ltd Cambridge, 2001
Anyway, both papers are really interesting. They propose methods to be more efficient and accurate with face detection (which is far from being perfect nowadays). A good lesson why math is important. (Support Vector Machines are not explained here). So take away:
the summary I wrote in order to get my credits (5 pages, pdf)
the presentation I gave (pdf, contains more cool pictures)
Since this seminar was in german, the outline is also (the german title of the book is "Geist, Sprache und Gesellschaft".