This page is my "blog".
It's just a place to leave some thoughts and things that are going on. Some will be about software, some about humans and some about both. I'll try not to post about the brand of my new toothbrush unless it's really important :-)
22 Oct 2017
Fairphone is making more steps to its goal of modular phones which are used longer (instead of, for instance, buying a new phone because the camera is a bit outdated). I have a (almost) two-year old Fairphone2, and making photos and videos is one of its most important functions. Thus, I bought the new camera module.
The new module upgrades from 8 to 12 megapixels, but there is much more to a camera than the pixel count.
Here I'll show a few before and after pictures for any Fairphone 2 owners who are interested. I'll show original first, then the new camera.
First picture: Objects in fall afternoon sunlight, no special instructions


The original camera did make some odd choices when making the picture, especially with lightning. The new module got it much better. This is also a reminder that a camera is hardware, but it needs software making good decisions.
Second picture: Objects in fall afternoon sunlight, focus on the sunflower


When I focused on the sunflower, the original camera made a better picture. The new camera, however, gets more out of the scene. The table isn't as dark, and the colours are generally more natural.
Third picture: Freezer magnets on slightly reflective surface


It's less obvious, but I think the new camera gets details like natural colours and reflections noticably better.
I also made a comparison picture in a quite dark setting, and both cameras made really different choices. The old one caught too much light, the new one slightly too little. I installed OpenCam to see what difference another camera app made, and that result was much better.
I recommend getting the new camera if photos are important to you (e.g. you make 90% of the family pictures with your Fairphone2 and you believe 45 EUR are worth catching scenes slightly more naturally) and also to not underestimate what a different app could do, as well.
10 May 2017
In which I show my solution for listening to audio and watching videos at home in the digital way, with an acceptable quality (for most people), but for a very little costs and almost no hassle getting it to work.
Here's the short rundown on requirements I had and maybe you also agree on (which in turn means you might want to read on):
- All digital (sound and video files & streaming services)
- hassle-free setup - this is for the bulk of people who like me, are not in for weeks of research or tooling
- very low costs
- no vendor lock-in & use of standards where possible
- acceptable (not necessarily the world's greatest) audio quality
- remote control for everything (by mobile phone or actual remote controls)
And here is what what I actually use:

PlayOn Harddisk Media player 40 EUR
Google Chromecast 39 EUR
Raspberry PI as music box ~70 EUR
Envaya Bluetooth Audio Player 140 EUR
--------------------------------------------------------------------------
289 EUR
Why? - So here's the problem
Listening to music and watching videos at home. Everyone (in a modern household) wants to do this, of course. These days, however, the number of choices how to do it is vast, to the extent that researching what to buy can take forever. You can also built and configure a lot of things yourself, for instance using a raspberry pi and a custom-made luxurious soundcard. I understand that there were tough choices to make 30 years ago, as well, like how large the TV should be and if gold cables are really needed to get everything out of your audio signal.
I believe that today the number of sources for media has increased (and I'm only counting the digital cases for me anymore, really), because next to playing sound and video files from your hard drive there are now a number of relevant streaming services you might want to use.
On the hardware side, a lot of devices are on the market now, which all do something to play audio to you, in varying locations and quality. In fact, it's a young market with a lot of companies trying to develop exactly what we need. It's exhausting to do research there!
A lot of these new solutions are designed to lock you in and to upsell, something Apple is really good at. They want you to buy something wireless for every room in your house and also for on-the-go and what started at 200 EUR ends up at 1300 EUR and you need to keep using this system from now on.
The (my) solution
So I decided to lower my expectations with respect to audio experience, otherwise I would never install something modern. Otherwise, I believe I got pretty close to my requirements. Let's list what I bought:
Harddisk Media player
This little device plays almost any movie file you give it and it comes with a remote control (not pictured). I like USB sticks, which I can place there, but you could also connect a computer network cable and read files from some place in your LAN. I bought this a few years ago for around 90 EUR I believe (it's out of stock now), but nowadays the devices all seem to cost around 40 EUR. Connect to your TV via HDMI and it works.
Chromecast
Google makes this nifty little device which connects to your Wifi and then lets you show most of the content your phone screen would show, but streamed fromt he Wifi via the Chromecast to a connected screen, i.e. your TV. Your phone becomes a remote control. For streaming a few things which are well-supported (Youtube almost all of the time to be honest), this works really well. You have to help ot find your Wifi but that is very nicely done. Its usability breaks down though if you are streaming content via an app that is not supporting it or if you do not want the whole Google app stack on your phone (like I'm trying to these days), so I'm eagerly awaiting more innovation in this gadget area.
Envaya Bluetooth Audio Player
The audio speaker is the area where one can lose the most time and money. I settled for a bluetooth speaker I can put anywhere I want, has decent reviews about its sound (not great, but reviews from people with better ears than me -audiophiles- are tiring), good bass, an AUX in and can even charge your phone. You could pay less money here, but it is something you'll use a lot. Using the AUX in, it can even give your TV watching experience a boost. This works out of the box.
Raspberry PI as music box
Streaming music to the speaker from the phone or laptop has its limits. It really occupies your phone for example, and if you want to play files from a hard drive you cannot reach that from your phone. So one might want to use a music server, which can be controlled from laptop and phone. Enter Pi Musicbox, a ready-to-use open source software package which can run a RaspberryPi for this purpose. Basically, it runs Mopidy, an open source music server oftwear, but neatly wraps it for perfect fit on RaspberryPi. The nice thing about Mopidy is that there a many mobile apps written for it, so you can control the Pi Musicbox nicely from a mobile device. Pi Musicbox plays files but also streams web radio stations and gives access to streaming services (though I cannot vouch for the Spotify support yet, still trying to get the most out of it - however, I still can use my phone here). By the way, the 70 EUR I listed above roughly cover the Raspberry PI (about 40 EUR) plus necessary extra things like an SD card, a case, power supply and a 32GB USB stick.
This gadget is the only one requiring a little work, but not much, as you can see:
1. put the Pi Musicbox image on a SD card
2. edit the config file so it finds your Wifi when it boots
3. put in the USB with your music
4. boot
14 Jun 2016
I dragged it with me after my contract ended in 2014, but I actually made a finished product out of my dissertation after all and defended it at the TU Delft this past May.

It was a pretty formal procedure as you can see, but quite a meaningful end to , and actually a fun day in the end.
The dissertation itself is available here officially, but also hosted by me. I'll post the propositions here:
1. Both the need for low computational complexity of bidding and for effective capabilities of planning-ahead can be addressed in a market mechanism for electricity, that combines the trade of binding commitments as well as reserve capacity into one bid [this thesis, chapter 3].
2. In settings where a uniform price changes dynamically over time and where these dynamics are influenced significantly by consumer behaviour, the ability of a consumer to comprehend price patterns increases if a large part of the other consumers reacts to price dynamics in a manner similar to how he himself reacts to them [this thesis, chapter 4].
3. Dynamic pricing for electricity can effectively reduce consumption peaks, also under the two conditions that the retailer promises an upper limit on prices and designs his pricing strategy for profit maximisation [this thesis, chapter 5].
4. A heuristic control strategy for a battery which is limited in capacity can be designed such that it has the following three advantages: it reacts fast, it can reduce overheating of a connected low-voltage cable significantly and (if prices are dynamic) it can partly earn back the acquisition cost of the battery by performing revenue management [this thesis, chapter 6].
5. There is not one silver bullet to the problem of how to manage a smart grid in the most efficient way. Each setting has its own requirements, given by its own set of stakeholders and design objectives.
6. To have a healthy and happy toddler is not to a small degree a matter of luck.
7. For the foreseeable future, concerns about privacy need to focus on computers and mobile phones, which directly expose political views and social contacts of their owner, rather than smart meters, which expose less meaningful data.
8. If users do not comprehend the reason why a novel technology interacts with them in the way it does, it will not be adopted, even if it is useful and resource-friendly.
9. Electricity grids are the largest man-made synchronous machines, and economies are the most complex man-made systems. To combine them leads to much more complexity than is commonly assumed, and the resulting systems will therefore never be completely understood.
10. In a referral network, where agents base their opinion about the performance of a service on those of other agents, it is beneficial for users if the agents forget old information at a comparable rate. [N. Höning: "Discounting Experience in Referral Networks", Master thesis, Vrije Universiteit (2009)]

I also was asked to write a very short summary, which might be useful here:
New developments require us to reconsider how electricity is distributed and paid for. Some important reasons are renewable energy, electric vehicles, liberated energy markets and the increasing number of smart devices. How we deal with these dynamics will affect important aspects of the upcoming decades, for example transportation, home automation, heating/cooling & climate change.
In order to keep the security of supply high and price fluctuations within acceptable ranges, we need to continuously make the decisions who will supply or consume electricity, at what price and at what time. The resulting complexity should not grow too high for small participants, otherwise novel technology might not be adopted. This dissertation contributes market mechanisms and dynamic pricing strategies which can deal with this challenge and reach acceptable outcomes in four relevant problem settings (mostly situated in lower levels of the electricity grid).
The most critical problem to address are intervals with very high power flow, or with high differences between demand and supply which need to be evened out. Such “peaks” can result in steep price movements and even infrastructure problems. We study decision problems that will arise in expected scenarios where peaks reduction becomes important. In order to arrive at an efficient and usable system, this research specifically looks into
Encouraging short-term adaptations as well as enabling planning ahead (of generation and consumption) within the same mechanism.
Ensuring that small and/or non-sophisticated participants can still take part in mechanisms.
Letting smart storage devices contribute to network protection.
We develop agent-based models to represent expected settings and propose novel solutions. We evaluate the solutions using stochastic computational simulations in parameterised scenarios.
A similarly high-level overview was given by me in a short presentation before the defense.
08 Dec 2014
Last week I attended DockerCon Europe 2014 which luckily happened in Amsterdam this year. I got my finger on the pulse of important developments in the ongoing evolution of the internet and a just-healthy dose of tech-optimism from current Silicon Valley prodigies. I thought I'd share my five favourite slides with a little comment on each.

The internet is still a technological Wild West. So many talented people. So much change and progress in technology each year. So many things you need to know to deliver something that doesn't break for some reason. So much still to achieve. Docker provides a usable (fast and well-documented) way to bundle into a container some things that you know are working, then upload this container on any server and expect this functionality to be up and running and simply work as you expect. It wasn't a DockerCon talk, but I like this short breakdown of what holds us back and why containers can help a lot (9 slides). At Softwear, we are using Docker both in the CI workflow and partly in production (by the way, let me know if you want to do influential UX or QA engineering work for us). The slide above shows the way of thinking going forward - build stacks from things you know will work and will also work together. Like Lego. Then make these light-weight stacks (your actual web applications) work together in creative ways. The current term for a picture like this is "Microservices". This slide from Adrian Cockcroft (who spent six years at Netflix) makes the point how useful Docker will be in more detail. Adrians presentation (all slides) probably generated the most food for thought. My favourite line (slide 26) is:
DevOps is a Re-Org!
meaning that software developers are taking over system operator/admin - tasks in any company which does not actually run data centers (which is becoming a very concentrated business nowadays).

Next, we get to some Silicon Valley - style notion of how suspected technology breakthroughs will change society. Docker Inc. CEO is asking here:
What happens when you separate the art of creation from concerns about production & distribution?
Subtly, there is a picture of the printing press. He wants to say that creators of web applications soon might need to worry less about how they will deploy their app such that it will work, as the "container revolution" will make this trivial. Of course, the web 1.0 kind of already did that for content. However, I can see how lowering a crucial technological barrier for inventing useful web applications can really be significant to innovation. We have a lot of content and ways to get it out there, now let us see what cool applications can be built to assist people everywhere in the world. And although we at this conference were a bunch of rich white males, poor people are hopefully getting access to cheap smart phones soon (Africa is a good example). I, too, find these times exciting. But I was glad to return to my normal life, and to cool down a bit.

This slide gives an indication of the scale of change we are seeing in the software world. Henk Kolk from ING told us how this large bank sees itself as a technology company now and removed everyone from their large IT team who can not program at least something. Being a programmer means being in demand right now but as his slide says as well, speed is key from now on. If you don't get on board with this new way of having tight control over your stacks, together with being totally flexible towards switching technologies, all you will be doing is to jump from one sinking ship to the next. I got both excited and chilled, actually.

An interesting take away of the current weeks is how Open Source currently works. Big money has gotten in on it, because in the software world, you have to invest in widespread and sustainable technology while also having a modern stack. This only works when an open source community carries the technology. Even Microsoft is coming around in major ways. Companies are actually employing the best open source programmers directly to stay on top of things. The industry is a bit different than other industries in this regard (hopefully actually leading the way). On the slide above, Docker Inc. CTO Solomon Hykes is giving us his current set of the rules that he thinks make a technology successful these days. As a consequence, Docker got some interesting new functionality (announced on the first conference day), but it was kept out of the core code - "Batteries included, but replacable".

But it is also not all agreement and happy collaborative coding. No, sir. The latest trend is that a company or a startup guides an open source technology. This makes progress faster and stable, but it can easily break if you annoy the comunity. Node was just forked, AngularJS is having a community crisis. The Docker community is also weary of the Docker startup Docker Inc. In fact, Solomon Hykes spent a lot of his time on stage at DockerCon Europe 2014 to discuss how he wants to succeed as a steward of the Docker technology, using a process he calls "Open Design" (see all slides here). There is an Open Design API through which all feature requests have to go, thus separating people acting on behalf of Docker Inc. from people acting on behalf of the Docker Open Source project - no matter which company pays them at the moment. They are creating and updating their own constitution which deals with this construct as we speak (of course in structured text files, so if you suggest a change, you submit a pull request). So the message of this slide above is simple and compelling:
The real value of Docker is not technology. It's getting people to agree on something.
Replacing "Docker" with any standard, this is something you could also have said during any time of rapid development and change. Interesting times.
P.S. There were some really smart people at this conference, building amazing companies and systems. We can expect to see a lot, e.g. from the Apache Mesos project. I could have chosen more technical slides for this list, but it would have taken me longer to explain why I fancy them. A lot of them were also quite intimidating, actually.
27 Mar 2014
I'm quite happy with how the visits to this website of mine have developed over the last year. Here are the monthly numbers:
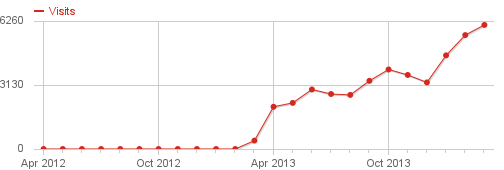
Btw, since March 2013 I use Piwik for my visitor analytics and am very happy. You should also be happy about that, because I don't store your metadata on Google's servers, only on mine.
An average week looks like this:
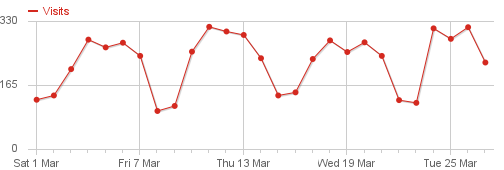
You can tell that people mainly come to my site on workdays, weekends are rather quiet. Why is that?
Well, in 2007 or so, I wanted to have javascript tooltips, or "popups" to display context to links when you hover them. I wanted to style them like I wanted. So I wrote a small script. It is very simple but the page explaining it creates almost all trafic to this website. Look at this example of page view numbers ("page views" are the amount of loaded web pages, where "visits" consist of one IP address performing one or more page views in one session) from (I think) one week:

The trend is clear. Around 300 people come to that page about the little javascript thingy every day, and not much else I write gets attention. And as you can tell from the long list of comments there, many people use this javascript thingy in the websites they build. I actually get some satisfaction in making them happy, so I answer many of their questions and actually improve the codebase once in a while.
But here is the problem: There are many other similar scripts for this out there, and I never get mentioned when experts list libraries for such a feature (I have been mentioned in two or three forums, I think). Why do people keep finding this? I think the dirty little secret is that I called it a "popup", while the technically more correct term is "tooltip". Look at search queries that people used when they came to this page:

There you go. Me and a significant amount of people use the slightly wrong term, and that's what drives traffic here. Accidental linguistic match-making in cyperspace. Positive things come from this. The traffic probably improves my Google ranking a lot. Our interactions help my users get something done and make me feel some fulfilment. It's a weird world.
Speaking of the world, here is where my visitors are from Mostly english-speaking countries where a lot of web development happens:

09 Jul 2013
On the way to the offices I work in, the bike path layout had a flaw: To reach Science Park (coming from Amsterdam center), one had to take a little detour. In the situation shown on the picture below, you had to follow the path on the left for about 200 meters and then turn right, in order to continue on the street in the background (here is the view from above). The more direct way, right down the hill, has been an emerging bike path for the better part of a year. It is now becoming an official bike path, as the picture shows (I took it only a couple of days ago).

While it was emerging, the path was muddy, and (especially on rainy days) quite difficult to manage, both down- and upwards. I spoke to some of my colleagues and everyone wanted to take this route, but until now only the young males felt confident enough on their bikes to do it.
Why did everyone feel strongly about taking this route instead of the slightly longer one? There is an emotional cost to pay for being forced to take a longer route, even if it is only slightly longer. Does this emotional cost justify the effort of building this new bike path? I'm not sure, but I sure can say that the city of Amsterdam has a bike path management that pays attention.
A rather famous example (at least in the scientific research community on emergent human patterns) of such an expression by users that their intent differs strongly from the planners' design is this (from an article by Helbig et al from 1997):

I'm not sure if the University of Stuttgart reacted to this, though, back in 1997. I tried to find that place on satellite images, but with no success. They probably redesigned it completely. Just as our emergent bike path, this one is, admittedly, not pretty to look at. However, the response from system planners can be quite different, apparently.
29 Aug 2011
I just spent a weekend in Paris, to attend the fourth European Scientific Python conference.
- A very nice and talented crowd of roughly 160 people. It was very well-organised, many thanks to the team who made it happen.
- Python has come a long way. I learned that Python detected the latest, scientifically sensational, Supernova explosion and will command an on-board camera in a robot on Mars in 2016.
- "Mr. ipython", Fernando Perez, gave an insightful keynote talk. He showcased a new kernel-clients model in the upcoming ipython 0.1.1. Not only can several clients work on the same ipython process, a client can now be anything ipython users ever dreamed of (or didn't even know they should be). First, Fernando showed a console emulation window written in QT. It had nice syntax highlighting, tex support, actually working multi-line editing and inline plots. Pretty neat. Then he showed a broser implementation, merged last tuesday, which they call the ipython notebook. Basically, the ipython session becomes a document, which is editable inline and at all times and can contain many content types (he easily inserted images, videos, math and javascript). The whole book can be saved as json. Fernando closes with the sad fact that less than 30 people do 80% of the work in many python scientific computing libraries (scipy, matplotlib, numpy, etc).
- I presented my simulation framework Nicessa on a poster and decided to give a short lightning talk about this vision of independent layers which seem to evolve in this community (Nicessa can be the middle layer):

- On the train ride back, I happened to sit next to Ralf Gommers, one of the few major SciPy contributors, by coincidence. Pretty interesting, not only because I actually started using SciPy in a research project very recently.
13 Nov 2009

When we use a common good, we cause the most expense and anger when we all use it at the same time. An idea that is now being tested in several places is to convince a small percentage of people to deviate their usage of the good from this popular time points. It is generally agreed that in many cases, a change in the behaviour of very few people can already relieve a system of much pressure.
The current consensus seems to be that the system operator should pay people for that. If someone actually has the flexibility to deviate, the opportunity to earn or save money might make him actually identify and use it.
I see this in electricity markets, where demand peaks can maybe avoided by convincing a couple of devices to stop operating for a while and also in traffic management: The city of Utrecht plans to pay a commuter €4 per workday if he doesn't use the highway A2. They will have to devise some solutions where they film the numberplates of passing cars, but building new streets might be much more expensive (not to mention how much trafic jams hurt the economy and the mental wellbeing of commuters).
This can be a very effective way towards more efficient usage of common goods - but there are hurdles like the increasing hunger for usage data that comes along with it. Not many people will like that and we will need to talk about this. The good news is that if the mathematicians are correct, not everyones flexibility is needed.
Update: The Netherlands now plan to tax highway usage for everyone via satellite by 2012 (like the Germans already do for trucks). This system is more flexible, but also harder to accept.
03 Nov 2009
I have been making the optimisation of systems, based on local information, one of my specialities. Such systems are optimised in a decentralised manner (which says that control happens on local levels and decisions about that are made also locally, according to local information). As such they are resilient against the shortcomings and the failure of a central planning node. That's good for users of the system. It also sounds nice. But is it really nice, in daily perception? Let's look at two examples:
 On dutch motorways, the control system sometimes imposes tempolimits (say, 70 km/h or 50 km/h) on parts of the roads in order to prevent traffic jams further down the road. So the system knows about congestion problems in the vicinity of you, and might slow you down so you do not make a traffic jam out of it.
On dutch motorways, the control system sometimes imposes tempolimits (say, 70 km/h or 50 km/h) on parts of the roads in order to prevent traffic jams further down the road. So the system knows about congestion problems in the vicinity of you, and might slow you down so you do not make a traffic jam out of it.
Recently some scientists modelled the problematic public transit system in Mexico city. Though buses run according to a plan, they sometimes stay in the stations longer (e.g. when a lot of people have to get in) and so they built up irregularities over a day, which ends up in a lot of buses being in one place and none in most others (this problem even has a name: "platooning"). They concluded that buses should just leave after a short time and not let all attending passengers board. Those passengers left out should take the next bus and overall, in the long run, everyone is better off because the whole system will run smoothly.
All this is true, but from the local viewpoint of the user of such a system, it feels wrong. I cursed when I rode on the dutch motorways and had to slow down for no reason that I could immediately apprehend. And it will definitely suck when a bus driver just leaves with you still standing right in front of the bus stop. We would hate those bus drivers.
I can tell from my own experience in understanding such systems (while researching them) that it would be hard to make everyone understand the situation. On the one hand, it's based on a lot of information and that information is decentralised - it is not all in the same place as a local observer. On the other hand, our brains are also bad at processing such abstract stuff like the platooning problem.
What to do? Would humans be happier with problematic systems, simply because they would feel more in control? Or can we evolve a system thinking in our culture that appreciates such complex, decentralised solutions? Maybe it would help to put out as much information as possible about how these systems work so that everyone can look it up herself. Maybe we'll need to go the extra mile and also visualise them really well. We should have graphically appealing real-time overviews of traffic situations (already in the making), public transports, elevators, electricity grid congestion and so on - for everyone to see and to discuss.
But I also think that in the end, not every optimisation procedure can actually be accepted - it needs at least to be understandable to stand a chance.
08 Aug 2009
When I run computer simulations, I have to have a solution for the same set of technical tasks each time:
- How to combine variable settings in experiments
- How to store log files nicely
- How to plot nice graphs from those log files
- How to run these expensive computations on remote servers (e.g. university servers)
Now I have one solution for all of this and I am very happy with it:
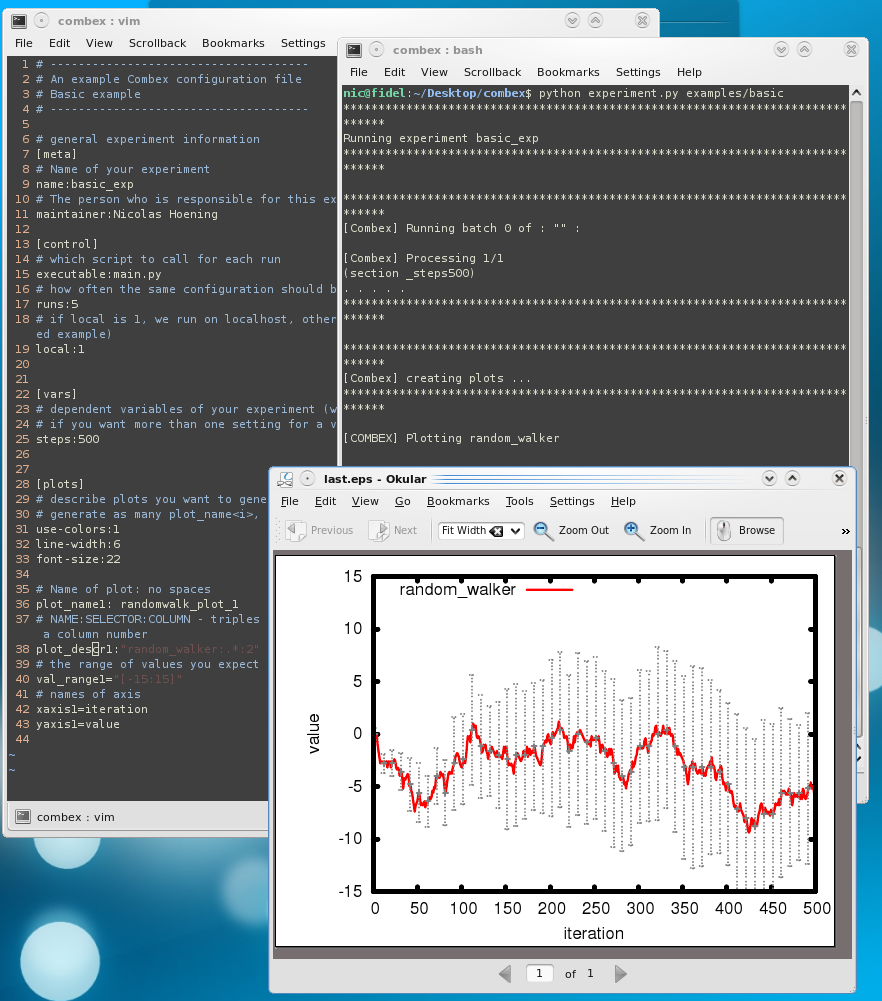
The above bundle of tasks is universal to a lot of scientists that need to to run computational experiments. I myself will run into this over and over again.
It is a natural reflex of a software developer to build a good tool for this over time and this is what I did. While working on several projects during my Masters, the latest of which is my thesis, I developed scripts for all of these tasks and bundled them together so that you could now call it an application: Combex (Combinatorial Experimentor).
It has turned out to be very useful to me lately and I would like to share this tool with anyone who is interested (this is its home). There are a lot of things that could be even nicer (I already maintain a ticket list), so I welcome contributions.
Note that Combex lets you program whatever you want in whatever language you want, all it wants is that you write log files.
I will let the (sparse) documentation speak for itself and just throw in another screenshot which shows how it all nicely comes together: A (dummy) experiment gets chopped into several tasks and those are shipped to remote servers. I can nicely check if they are done. If so, I have Combex get the data and generate nice plots.

P.S. To talk about our process and find general, reproducible solutions seems to be a general trend in science, see e.g. myexperiment.org.
P.P.S. I am unaware of any other software that offers this task bundle, even if its commercial. Anyone knows software like that? I only found quite specialised approaches, but what I like about Combex is that it doesn't care what the hell your code is doing as long as you configure variables and log data. It is more of a very simple workflow with nice tools along the way. In principle, a lot of other software (say, statistical processing) could be hooked into this as needed.
P.P.S. I am still open to be convinced by a better name for this.
P.P.P.S. It has now changed name (it also evolved a lot) and lives here.
22 Jun 2009
I recently accepted a new job. From October 2009 on, I'll be a junior researcher at the CWI (Centrum Wiskunde en Informatica), a national research center here in Amsterdam. I'm very happy to be working with Prof. Han La Poutre.
I will actually be a Phd student but do research in a predefined context - nowadays, a lot of Phd positions in the exact sciences are a mixture of research work and research exploration. An exciting part about this project is that it is about a very real challenge and there are many stakeholders involved whose views on the problem are important. I will do fundamental research on dynamic and adaptive multi-agent systems, but I will also be busy wearing the hats of different stakeholders and try to bring their view into the model.

[image via http://www.usgbc-centraltexas.org]
The project I'll be working on is called IDeaNed (Intelligent en Decentraal Management van Netwerken en Data, only dutch description so far). It deals with one of the big challenges we face in the next years - a redesign of our energy distribution networks.
As we begin to exit the age of fossil energy, energy will soon become a problem for us, not a cheap and abundant catalysator for progress. Now, as an AI researcher, I can't help out where it is most important - say, actually invent an effective renewable energy source or useful, longlasting batteries. But what we need for sure is a new energy infrastructure. There is already a term for this - the "Smart Grid"*.
Our existing energy networks are of an old, centralised design which is not suitable for the way we need to look at interconnected things. As the report "Grid 2.0" (PDF) puts it:
"It is hard to make the link between flicking a switch and the distant power station that made it possible to turn the light on.
(...)
Partly as a result of this lack of a feedback mechanism, and partly because of technological constraints, Grid 1.0 is surprisingly inefficient. Only around 40 per cent of primary energy input (coal or gas) used in power stations is converted into usable electricity, the rest is wasted heat. A further nine per cent is lost as the power moves through the transmission and distribution system. Then a further third is lost in our homes and offices because they are poorly insulated, not designed with energy in mind, and inhabited by people who do not see themselves as players in the energy game."
We need a network that is decentralised (can work with input from several local sources, not only big central plants, can communicate locally about sharing loads) and avoids efficieny problems in peak times. Such a net needs real-time price mechanisms and needs to accomodate a lot of players: customers want to use effectively, producers want to sell efficiently, governments want to distribute evenly **. Meanwhile, there is a real, non-abstract component: the network. Voltage capacities at different parts of different sub-networks dictate what is possible and what is expensive to do. A lot of these things change all the time. This can get very complex very fast.
What we'll be doing is modeling Multi-Agent systems in order to learn what good price mechanisms are and what good automisationable strategies of the local players could be. We will get input from another Phd student from Eindhoven supplying technical findings about the infrastructure and we'll work with companies in the dutch energy market (big players and consultancy agencies that develop energy network simulation software). This highly integrated approach of designing scientific projects is a unique dutch approach and I am quite excited about it.
This topic is not only being picked up in the Netherlands. Big companies like GE or IBM are already promoting their competence in this topic which isn't even entirely understood yet.
They smell money in creating a market better targeted at our actual energy usage and in savings due to efficiency. This might be one of the rare cases where what they want and what society needs have a significant overlap. For instance, I recently learned that energy efficiency on the last mile is multiple times more effective than energy efficiency at creation time (due to all the energy losses by conversion or distance that already accumulate until the last mile). And it is easier to do.
* There might even emerge a bubble with all the money being thrown at this topic right now by governments, but I hope that in 4.5 years, when I finish this project, things will have come to terms, the crooks took their money and left or were thrown out and we know where to go.
** Especially when there is not enough. In a post-fossil world there may be "bad weeks" with few energy available. Or, in more grim scenarios, we'll have few energy at all times and almost none in "bad weeks". Making sure distribution can be fair is crucial and not as easy as it first sounds.
17 Mar 2009
I am currently reading The Origin Of Wealth - a book which tries to explain in what deep explanatory troubles classical equilibrium economics have gotten into during the last two decades.
One of the main messages is that economic systems are no closed systems that could theoretically reach an equilibrium - they are highly dynamic and interactions are so complex that they will only -suddenly- reach an equilibrium when all involved players are dead.
This simple drawing I made should resemble some of the most basic physical classification of systems and where economic systems belong. The author says that classical economics would want to place an economy in the right branch and therefore never have a model close to reality.
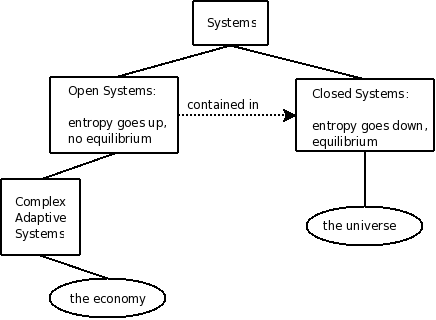
After economics borrowed the notion of an equilibrium from physics (roughly 100 years ago), physics moved on and discovered entropy and the second law of thermodynamics. Chaos and Complexity have now been discussed fundamentally by almost all basic sciences, but seldom in economics.
Later on, the book discusses that in an open system like an economy, the creation of (temporary) order is what we call "wealth creation" and that this happens by evolution-like processes (the best system/solution/product replaces others):
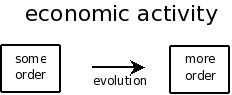
I am interested to see how the author defines a "complex adaptive system" (which is his own term) later on...
10 Mar 2009
I got my new MacBook some days ago and am very happy. Especially having a built-in webcam feels very much like finally being in 2009. Visiting my friend Marcel in Osnabrück, I tried out Photobooth, a nice app to make pics with the webcam. It's great fun, not only for kids:

Here are our best shots :)
27 Feb 2009
Here is a result from the group project.
To summarize shortly, the job description was to take an emergent system (where the exact outcome can't be controlled for in advance) and inject some agents that prevent some behaviour from happening. This could for instance be an effect you as a system designer don't want while you still want to allow the system to freely find other solutions.
In this little animation you can see the first proof of concept in a Particle Swarm Optimization. In the middle is a local optimum (darker background is optimal) and the grey agents try to coordinate in luring normal (red) agents to the hard-to-find global optimum in the upper left corner. Everything still happens decentralised.
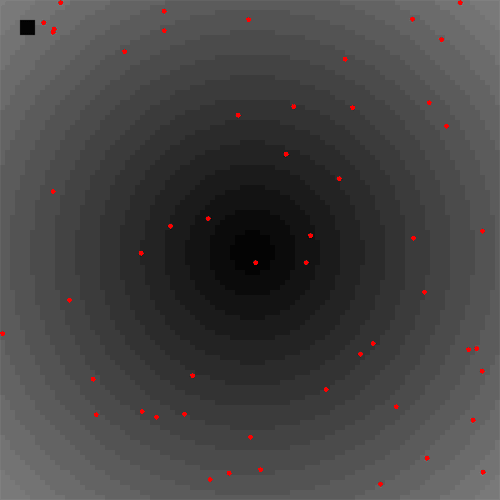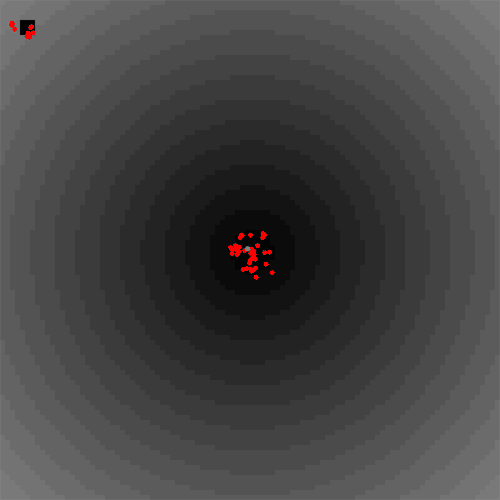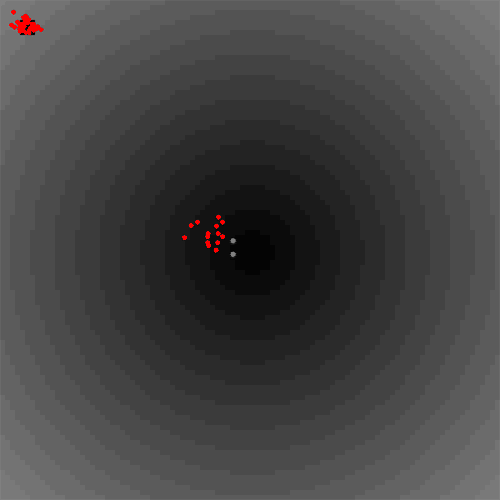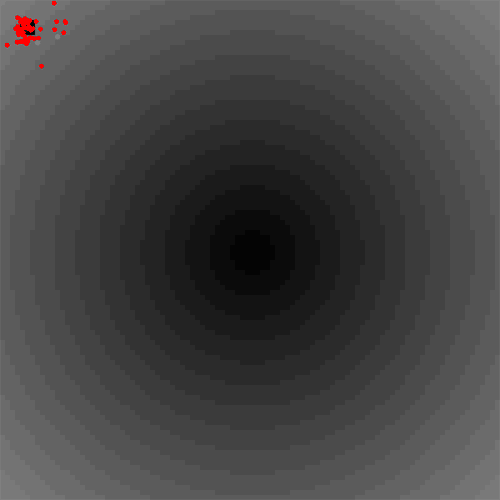
It was fun to put it together in roughly two days, but now the tricky parts would begin:
- This example with only two control agents worked well, but it all depends on the settings: What are good parameters to adjust the control agents (e.g. the ratio of control agents vs normal agents, what is k in the k-nearest neighbour approach, why do sometimes equilibria exist that seem hard to explain right now?)
- In what direction should research in controlling emergence generally go? Martin Middendorfs initial approach [1] is interesting, but also just playing with the idea.
Update: Jeff Vail has some thoughts on "Guided Emergence" in Biology, the War on Terrorism and the Military.
[1] D. Merkle, M. Middendorf, A. Scheidler. Swarm Controlled Emergence - Designing an Anti-Clustering Ant System. Proc. IEEE Swarm Intelligence Symposium, 8 pp
27 Feb 2009
I'll do a three-piece blog series about cooperation - well, at least about some basic terms I've been thinking about, in order to clarify them for myself. This first piece will deal with cooperation as a research objective. Later, I will argue why I think cooperation is a formidable objective for Artificial Intelligence research and why it's a good idea to study network structures along with it.
Basic Definition
To cooperate basically means to do something together. The research I deal with is especially interested in situations where altruism is needed for cooperation, i.e. you have some initial costs if you cooperate. Then, the question the cooperator can ask himself is "Will I be repaid?".
The Dilemma
In many situations in life, you will be repaid. But if you want to be rational about it, there is always some uncertainty. Moreover, cooperation may or may not have some overall benefit for you after you've been repaid, but if you cooperate and get screwed over (not cooperating is called "defecting"), you may lose your whole investment. So there is unbalanced risk, favoring defection. The uncertainty about this is higher if you know less about the situation you're in.
The dilemma is as follows: If you don't plan ahead (maybe due to uncertainty), defecting is always the best option. If at all, cooperation only repays in the long run and if you don't get defected too often.
We all know that cooperation happens every day, even with big uncertainty, in humans as well as in almost every other life form imaginable. It has been proven that humans are even hardwired to cooperate, for instance via the oxytocin hormone (see for instance this book by Joachim Bauer) *. The question is how it came to be.
The Prisoner Dilemma
A really nice way of putting this dilemma into numbers is the Prisoners Dilemma. I'm not going to reiterate the basic "prisoner" setup (which was just a story to make the dilemma clear). If you look at the payoff matrix below for a while, you'll notice how the numbers express the dilemma: to defect will not hurt, but might payoff big time - cooperating will not yield that much, but may hurt dramatically.

Why is it nice to have this dilemma formalized so simple? Now you can setup different worlds, simulate them or prove mathematically that a certain setup is good for cooperation or not. It's a great tool. I'll talk more about this in the next post on Cooperation in AI research.
To finish this, I want to highlight some approaches to explain why systems have cooperation. It's amazing how long it takes to come to reasonable theories for this:
Survival of the fittest (Spencer, 1864)
The survival of the fittest is a dangerously extreme notion of individual success. This notion would only opt for the short-term notion of the cooperation dilemma (saying that defection is your best option, always), and is therefore stupid. It has been attached to Darwins ideas of evolution for a long time and to explain cooperation it is often changed to somewhat more meaningful concepts:
- Kinship selection - A very popular concept among scientists is that you're more likely to cooperate the more related you are to your opponent genetically. This notion is carried by the belief that genes have been favoured in evolution that make their carrier do beneficial stuff for similar copies of them (i.e. for related carriers), where you are related 1/2 to each parent, 1/4 to a sibling and so on. They even try to get these numbers to show up in psychological results (it gets problematic right there).
- Group Selection - For cooperation outside of kinship, people just bend the survival-of-the-fittest metaphor to several levels and say that there is selection pressure on whole groups and if only its members cooperate, the group is stronger than other groups. You can find proponents for this from Kropotkin to Hitler.
Both of these subtheories make some sense in specific situations. If I ever happen to die in a fight to the death, then certainly the survival-of-the-fittest approach would be suited best to explain why I didn't survive. But none of these approaches is in any way general. There is certainly cooperation without kinship (called "reciprocal altruism"), and when everyone is connected to everyone, how do you define a group?
Systemic approach
There is a need for approaches that approach conditions for cooperation more systematically. For instance, one very important property of a cooperative system is that altruistic acts are superadditive (meaning that such an act generates more utility than if the two participants had just acted alone - the utility can still be shared unequally). When you look at cooperation in systems, you are more interested in the behaviours of agents than their interiors. You care more for the dynamics of all interaction patterns than if A would beat B in a duel. This is an approach we need while we realize how complex all our networks are.
I found a promising model by Fletcher and Doebeli (2006) [1], who connect Hamilton's rule with results from D.C. Queller (which are from 1985!!). While Hamilton's rule explains in simple terms that cooperation works well if the cooperators are related on the genotype, the rule can be generalized to the relation among phentotypes. In other words, systems that have some properties that support cooperation, will have cooperation. It matters that altruists benefit each other. I quote from Fletcher and Doebelis conclusion:
"What this rule requires is that those carrying the altruistic genotype receive direct benefits from the phenotype (behaviors) of others (adjusted by any nonadditive effects) that on average exceed the direct costs of their own behaviors. Kinship interactions or conditional iterated behaviors are merely two of many possible ways of satisfying this fundamental condition for altruism to evolve."
I hope I have motivated how research generally deals with cooperation, or at least what tools I think are appropriate. The next post in this short series places cooperation in the context of AI research, which mostly should answer the question why anyone would want to build cooperative systems (until now, I was talking about explaining them).
[1] J.A. Fletcher & M. Doebeli, Unifying the theories of inclusive fitness and reciprocal altruism, The American Naturalist, 2006
* Of course, too few cooperation also happens. The Tragedy Of The Commons models situations in which agents use up a depletable common good (for instance a water well), thinking only in short terms.
25 Feb 2009
Anders Johansson gave a great talk here at Decoi 2009 about the work Dirk Helbig directs (he is currently in Zürich - here is a 3Sat video of a german interview) concerning the simulation of pedestrian crowds. This research has over some years evolved to a rich set of tools and he was able to entertain us with nice 3D-videos of their simulations. I will shortly highlight the main topics he addressed.

The social force model
Their model is based on a swarm algorithm: Agents (the pedestrians) follow their own goal, but are influenced by others (others can be other agents or walls). They want to be close to others, but not too close (this is called "repulsion"). Then, they added to this proven local algorithm what they found useful. For instance, agents have individual traits like acceleration (how fast they can be and how fast they reach this best tempo).
You can also describe the external forces influencing an agent as physical (strong, but short-lived) and social (not so strong, but affect the agent longer).
By illustrating each step in the model building with a small 3D video of people approaching each other, we really could watch the model becoming quite realistic.
Real-world data
A lot of the work has been done in extracting real-worlf behavior from videos. They filmed people moving through metro stations and shopping malls. It is a quite demanding task to extract all individual pathways from the video, but they have a good algorithm now to do it. Then, they can replace one agent in the extracted data with one simulated agent (who works according to their model) and find out how good the model predicts what a real human does. Do this a lot for many combinations of people and adjust your parameters a lot, and you can make your model better.
It should be noted that of course the video can't tell which intentions humans had - if someone remembered he forgot something, he'll turn around. Also, the real humans had a high variation in their behaviour.
Evolution
Some work has been done to evolve an agent strategy via a 'blind' evolution algorithm that just tried to evolve a model that predicts human behavior very well (you notive that this is a bidy of scientific work spanning years).
Macro Level
Now, when you look at groups of pedestrians from a macro level, you can describe crowds in several ways:
- when groups of people have contradicting targets, they tend to form lanes (at least this happens in Europe). If the streams of people hit each other diagonally, the form stripes (this looks fascinating).
- When the space which pedestrians move through gets more crowded, the mass of people moves through different stages: First it tends to progress in Stop-And-Go Movements. When it gets even more crowded, turbulences occur in which most people just get pushed around slowly in random directions. Interestingly, some simple models had predicted that crowds at some point will just stop moving, but that actually never happens.

Real stampedes
The research group also studied real mass accidents that happen in night clubs or football stadiums around the world. In fact, Anders just arrived from Saudi-Arabia, where Scientists study the mass accidents that regularly happen during the Hajj in Mekka. We got introduced to the terrain and special problems of this occasion (for instance every single of this 3 million people needs to do the exact same thing at the exact same place). We saw some stunning videos from 2006, when they started to film the crowds (luckily, we didn't saw the big accident of 2006 itself). for the next Hajj, the organisators took several measures like defining routs in which to go (slowing down traffic and leaving areas free for emergency support), building important bottlenecks over several stories and simply registering a considerable amount of visitors to be able to spread them over the week.
Accident prediction
A nice feature of a model would now be to predict an accident from such a video. They found that a measure called "gas-kinetic" works best for them. This indicates the crowd density and the variation in velocity. When both are high, an accident becomes more likely. However, they are hard to predict. In almost well-known examples, something innocent triggered the mass panic (like a fight between two women in a Chicago night club or the rumor about a suicide bomber in Karbala, Iran).
08 Jan 2009
I am having a rough semester, group-wise. I think that group work at universities is still pretty immature.
.jpg)
Here at the Vrije Universiteit (like in many universities these days), group work is an important concept. To put students in groups saves the lecturer the hassle of evaluating 30 projects. Instead, (s)he evaluates 10 projects. Then, projects can be more ambiguous. Of course, group work also prepares students for the complex work life, where nowadays collaboration is an important ... and so on.
My point today is that group work also introduces new problems, problems that are not properly dealt with. Most of the times, a group is assembled and you have to work together with some guys you never met before. Yes, this is where the soft skills get developed. But what if one or more group members are clueless and/or lazy? The last thing is often worse and it happened to me in almost all courses this semester. I worked really hard, while others profited and got the mediocre grades that I almost single-handedly achieved. Meanwhile, I couldn't focus on other stuff like exams and also got mediocre grades there. I am pissed, mostly because people can behave like dicks right in front of me and get away with it.
Of course, this also happens in the real world. In fact, I know that it happens all the time. But in the real world, there is often something you can do. You can leave and add your work force to a better group. You can fire someone. People can get different payments because their contribution to the project is different. In the real world, there are potential drawbacks for slackers. Currently, in most courses at universities, there is none. You have to stay in your group. Everyone gets the same grade.
What I am saying is: if you create group work, fine. But if you let the work of individuals be invisible, you create incentives to cheat. If you grade everyone the same, you show that underperforming pays off. If you don't allow people to regroup, you are a Stalinist.
A group needs to be able to react to conflicts in a way that matters.
There are so many tools out there that make online collaboration trackeable. Tell students to use them and monitor them in case of conflicts. Make conflicts visible. Introduce a sensible rating among group members and act if there are disparities. Make it possible for members to leave a group. There is so much to do that would raise the quality of work and the motivation of students that are not trying to get through on the back of others.
Update 12.01.09: In one of the project, one that still goes on, I decided to talk to the supervisors. One normally doesn't want to do this, because it feels like telling on your colleagues. But by this time, I had become so angry *, that I didn't consider my group members colleagues anymore. I have to say that when the supervisors are really monitoring group work (in this case by group meetings and presentations), then they can and sometimes will react properly. In this case, they had also suspected what I was describing. After they questioned the rest of my group about their subject knowledge, they decided to split the group. Maybe that is better for everyone. The supervisors really took time to resolve this and had indeed prior knowledge, albeit coarse, about individual work. If they do good work like this, I do think that supervisors should take a minute at the beginning of a course to mention that they will also keep an eye on individual performance (and there might very well be differing grades) and will react to problems in groups (and not just the "Hippie-way"). This helps the incentive.
By the way, this was in a group of three (where they normally preferred a size of two). Group size is also very important. A group shouldn't be too big. I had one course this semester in a group of five and that just spells disaster in this setting.
* I was angry when I wrote this rant, in fact - so I now reformulated two or three adjectives in the text.
20 Dec 2008
 In recent years, mind-doping has moved from science fiction to commonplace, at least that's what they tell us about US universities. Here is a recent article from the german "Die Zeit" and it is also a scenario discussed in the book "Radical Evolution". Students take cognitive-enhancing drugs like Ritalin (there are many more, it is a hot market) to get ahead of competition during exams. US researchers are now demanding to talk openly about it, and are provocatively proposing to give all students access to such drugs, for equality. Neuro-enhancement will come, the only question is when, how and of course the price.
In recent years, mind-doping has moved from science fiction to commonplace, at least that's what they tell us about US universities. Here is a recent article from the german "Die Zeit" and it is also a scenario discussed in the book "Radical Evolution". Students take cognitive-enhancing drugs like Ritalin (there are many more, it is a hot market) to get ahead of competition during exams. US researchers are now demanding to talk openly about it, and are provocatively proposing to give all students access to such drugs, for equality. Neuro-enhancement will come, the only question is when, how and of course the price.
This is scary, not just because it feels not right to a lot of people. It also says that there will be a more direct mean to turn money into success. If you are rich, you can afford the best drugs to make you more able to perform, to concentrate on only one thing, and so on.
But maybe, hopefully, this is not the only road this can go down. Paul Graham recently talked about why he thinks a successful society relies less on short-term evaluations like exams and more on actual, long-term successes like finishing a project at work or founding a startup. A society should define its success in keeping direct influence from money to success down. He sees a difference in the US a couple decades ago to the US now - money hogs like elite universities and big corporations have become a little less relevant (meaning: they don't hold the monopoly on the road to success anymore) *.
There are some drugs that might translate into medium-term success - for instance, Provigil lets you depend less on sleep and is taken by military pilots. But for these things I see a reasonable middle ground. People who overdose will not have long-term success. It's just like workaholics tend to break down after some time.
I hope that the trend Paul describes is real and will hold. Like all effects we have on the world should be valued more by their sustainability, we also need to regard human work success under the view of sustainability. I don't see a drug at the horizon that not just makes you a better performer, but more "intelligent". For me, intelligence is a long-term concept.
* Of course Paul promotes startups as the new thing in the rest of this article. He is advertising his startup seed company. But let's not bash him for that right now. I like to think of "startup" as a broad term, and be less enthusiastic about them how they are today and then Paul actually sounds reasonable most of the time.
28 Nov 2008
 Dr. Moira Gunn interviews Keith Devlin, author of "The Unfinished Game" (22 minutes).
Dr. Moira Gunn interviews Keith Devlin, author of "The Unfinished Game" (22 minutes).
He talks about letters that two mathematicians -- Pascal and Fermat -- exchanged in the 17th century. They pondered over a really simple gambling problem: The unfinished game.
To describe uncertain future outcomes in numbers was Pascals simple answer - and it is the foundation of probability theory. From that followed the modern finance and insurance systems we see everywhere.
The interesting thing is that Fermat quickly came up with a simple solution that today everyone will understand. It's teached in 6th grade. But Pascal, one of the best mathematicians that ever lived, didn't get it. Putting numbers on future events was a new kind of thinking. Framed like this, it's a powerful lecture about how culture changes thinking over short time spans.
13 Oct 2008
I am following the development of Amarok2 since a week. It's near completion, though still a little buggy. The second beta was just released.
I noticed that if you use a software everyday, you build a relationship. I donated some Euros to the Amarok team yesterday and I decided to run the beta despite some crashes since today. I do appreciate a fresh spirit in my music listening. Thanks, Amarok team.
Now. The main concept of the latest KDE 4 software is to have widgets (I especially love Folder Views). So in Amarok, too, you get an area (between media area on the left and playlist on the right) which you design yourself. Well, at least you decide which widgets you want to have.
In this screenshot, you can see that I opted to see the lyrics for the actual track and the Wikipedia entry for the artist:

Especially the widget area could use more programming love (You can zoom in, but not in the nicest way yet. Some widgets still crash.). But I must say that with KDE4 I became a real KDE fan. Thanks to Pete for encouraging me to try again.
P.S. The playlist there was assembled randomly. I skipped Robbie Williams.
17 Mar 2008

There is a beginning discussion that the wealth difference between the West and other parts of the world is not just a result of mere aggression. And it is not only noticed in the West. As others realize their shortcomings, the West has to work even harder.
Don't get me wrong, there is aggression out there, but a lot of people recognize that it doesn't make up for the whole equation. Writes Jeff Vail:
I can think of one justification that remains to some degree in America—we still seem to be better than anyone else in the world at combining just the right mix of structure and freedom, discipline and creativity, conformity and rebellion to create the kind of synergy that drives business innovation. That, too, seems to be changing, but for now I think it still justifies some kind of multiplier—but this mix is also subject to the forces of globalization.It is too few people who see that this cultural difference is not only something we should defend and strengthen (e.g. against islamistic threats) for moral reasons or because we owe it to our forefathers who achieved all this. It is our most important asset in the game of wealth. It is what sets us apart and makes our wealth possible. And it is no constant. It can go away.
However, I am not posting this to make that point yet again. I came across two sources that show how this reasoning makes its way into scientific discussion:
Study finds anti-social punishment in more traditional societies, dragging profits down
A recent study by Herrmann, Thöni and Gächter (published in Science magazine) conducted cooperational games among students in a world-wide experiment. Groups that cooperate can maximize their profits, but individuals can also defect the others. In addition, punishment was possible. The paper can be found here (without paying a Science magazine fee) and a comment that also appeared in that Science issue is here. It concludes:
A few subjects, when punished, rather than contributing more, suspected that it was the high contributors who punished them, and responded with antisocial punishment: They punished the high contributors in future rounds, leading the latter to reduce both their contribution and altruistic punishment. Herrmann et al. collected data in 15 countries with widely varying levels of economic development. The subjects were university students in all societies. The authors found that antisocial punishment was rare in the most democratic societies and very common otherwise. Indexed to the World Democracy Audit (WDA) evaluation of countries’ performance in political rights, civil liberties, press freedom, and corruption, the top six performers among the countries studied were also in the lowest seven for antisocial punishment. These were the United States, the United Kingdom, Germany, Denmark, Australia, and Switzerland. The seventh country in the low antisocial punishment group was China, currently among the fastest-growing market economies in the world. The countries with a high level of antisocial punishment and a low score on the WDA evaluation included Oman, Saudi Arabia, Greece, Russia, Turkey, and Belarus.
China reassures scientists not to fear failure
This news is big:
China will tolerate experiment failures by its scientists to ease pressure, encourage innovation and cut the chances of fraud, a top official said on Thursday.
China recognizes a cultural shortcoming in its scientific community. The ratio of worthless or even wrong studies is far higher than in the West. As far as I know, this is not rooted in the very old chinese history. But at least in the last 100 years, China has built up a dangerous perfection cult. Dangerous for its own progress, that is. It is politically remarkable for the change China is going through that this is acknowledged.
So, while the Middle East suffers from its honor culture, China wrestles with perfection cult. I am not saying that we don't have cultural problems on our own. My point is: (at least some) others are working on their self-understanding. Let's start working on ours again.
* image by tarotastic
10 Mar 2008
I recently came around to get pictures off my mobile via bluetooth. They have been locked in there a long time.
A lot of them I had completely forgotten or never looked at on a real screen. The camera is not very good, but sometimes I obviously saw things that the world needs to see anyway. Here a some jewels:

In the library of the university of Osnabrueck: Lexicon of nutrition. Volumes A to Fat, Fat to M and N to Z.
On the train station of Muenster, Germany. If you would really spell Osnabrueck like that, it would sound as if Adolf Hitler says "Osnabrueck".

Seen in the window of a turkish supermarket in Osnabrueck: "Smartklamp: Circumcision with one click!" If this is satire, it is damn good and the place of action has been well chosen. If not, I have nothing to add.
Update: Jan found out that it seems to be for real. Ugh. But at least the company's site is down. Maybe a rabbi or whoever does it is still the way to go.

One of my first trips to Amsterdam in search of appartment and a new life. But the Blue Screen Of Death is everywhere! I bought my ticket elsewhere.

This is how you transport kids and other stuff on your bike in Amsterdam.
19 Oct 2007
During the 77 year celebration for the institute of sciences ("Exacte Wetenshapen"), I took part in a Salsa workshop. Now, pictures emerged on the interwebs. I am the one with the black hat.

Thank god, I am not making terrible mistakes on any of them :-)

It was fun, though. And a great buffet.
[pictures from fotorene.nl]
10 Jul 2007
For my Bachelorthesis (I write it using Latex), I wanted to have little bordered textboxes that would float next to the main text.
They should explain terms that are mentioned in the main text, so that everyone could read more about that term if (s)he needed to.
It turns out that this is no easy task with Latex. All standard elements I tried would either not float very good, have no border and/or failed to wrap the lines within the info text.
I spent three hours to come up with a nice solution, so it might be useful for people if I share it here.
I defined a new command in the top of the document:
%%%% Custom Command for floating Infoboxes
%%%% usage: \infobox{<title>}{<text>}
\usepackage{picins}
\newcommand{\infobox}[2]{
\parpic(0.34\textwidth,0pt)[lf]{
\parbox[b]{0.32\textwidth}{
\bigskip {\bf #1} \small{{{\sffamily #2}}} \bigskip
}
}
\bigskip
}
The picins package is normally used to place pictures within the text, but when I place a \parbox inside, it works really nice for text.
To create such a infobox somewhere in the document, you just use it like this:
\infobox{XSLT}{
XSLT is a stylesheet language that can parse XML files and transform them. The output will be another text file, possibly XML. It offers a lot of capabilities as it is a fully functional programming language.\\
Like XML, XSLT has also been specified by the W3C consortium.
}
Here "XSLT" depicts the bold-faced title within the infobox and the second argument is your info text. Here is a screenshot that shows how a result will look like (I bold-faced "XSLT" in the main text myself):

The text block that the infobox floats around is simply the one it precedes in the Latex document. You can also have the infobox on the right. Give the parpic command "rf" instead of "lf" as an option.
The picins command is praised as a really nice package, but it has some problems: If the remainder of the paragraph text is insufficient to fill the area to the side of the infobox, the text from the following paragraph will run through it. It also won't work with enumerate/itemize besides the text. Both of these issues can be fixed on a case-by-case basis, but it can be nasty...
Feel free to drop me a comment if you like it / can do it better / can make it more beautiful.
Update (05.08.2007): I made the height of the infobox independent of the text length and used sffamily for the font. I now also mention some problems with picins that I (and others) ran across.
10 Jun 2007
For my web CMS "Polypager", I recently put a CAPTCHA mechanism into use (CAPTCHAs help to block comment spam by asking commentors to identify text from pictures, a task where humans are still much better than computers - I wrote about them in a previous blog post).
This is what it looks like:

It's a cool one, a service by Carnegie Mellon University which lets people identify two words. One is to make sure you are human and the other helps digitize books from libraries: Sometimes the software that scans in those books is not sure what to make of a word so people who want to write a comment can help.
So in this example, typing in "overlooks" may assure my CMS software you're a human while typing in "inquiry" helps to identify this word, which is a problem for the book scan machine of Carnegie Mellon (it could also be the other way round, who knows?).
For a year or so, I had tried other tricks to prevent comment spam, requiring no extra work by the user. But recent developments by the spammers seem to have taken those hurdles. As hundreds of spam comments rolled in, I had to take some action.
Anyway, though it's a really nice idea and all, I do fear that this secret from postsecret.com is really wide-spread:

I think the point behind this secret is that simply reading and entering text is too dumb a task - solving captchas should be fun, not work. Even the Hot-or-not approach is more work than fun. It's always the same task. Repetition is never fun for humans. Only machines like it.
Let's crunch some numbers: The recaptcha guys claim that "About 60 million CAPTCHAs are solved by humans around the world every day." Say that one of them takes 5 seconds to solve. That amounts to more than 3,400 days of time - and it seems that people regard this time as labor!
What ideas could we think of that make assuring that you're human more fun - like a little 5-second-game?
Here is one: You heard of this place called Web 2.0 where thousands of users generate content and the site creators do nothing but provide the platform?
Why not create a CAPTCHA - platform like this?
Users submit little riddles, you know, obvious ones that you can solve really quick. Just a little picture and a one-word solution to it.
Here, I made a quick example (using Incscape):

I know, it's not beautiful and not funny. But it's different. Everyone will submit different riddles. That's what humans like: "Gee, I wonder what kind of riddle I get this time!".
The fun part here is that they all come from different sources. Each one is different: some are funny, some have a message, others are beautiful ... you get it.
Let's assume it would work in the Web 2.0 manner and thousands or millions of riddle - CAPTCHAs come together, new ones all the time. They would be very, veheery hard to crack using machines. The spammers would have a hard time defining the problem space. They just wouldn't know what to adjust their algorithms to.
I hear you say that people would never submit riddles to a platform in satisfying numbers - but that is the same argument they brought forward when Wikipedia and YouTube started.
So, the riddle CAPTCHA platform already has some Web 2.0 features like user-created (and user-owned) content. We don't need to add social networking, but let's add the Architecture Of Participation:
Riddles could be ranked. Each commentor is asked how (s)he liked the riddle (this requires just one click and is not mandatory). This would create the popularity contest that Web 2.0 people like so much. However, the popularity of a riddle would not be reflected in the number of times it gets used. That would be too easy for the spammers.
Alright, that's how far I'm pushing this idea forward for now.
If anyone has objections why this is a bad idea, please comment.
This is what it looks like:
It's a cool one, a service by Carnegie Mellon University which lets people identify two words. One is to make sure you are human and the other helps digitize books from libraries: Sometimes the software that scans in those books is not sure what to make of a word so people who want to write a comment can help.
So in this example, typing in "overlooks" may assure my CMS software you're a human while typing in "inquiry" helps to identify this word, which is a problem for the book scan machine of Carnegie Mellon (it could also be the other way round, who knows?).
For a year or so, I had tried other tricks to prevent comment spam, requiring no extra work by the user. But recent developments by the spammers seem to have taken those hurdles. As hundreds of spam comments rolled in, I had to take some action.
Anyway, though it's a really nice idea and all, I do fear that this secret from postsecret.com is really wide-spread:
I think the point behind this secret is that simply reading and entering text is too dumb a task - solving captchas should be fun, not work. Even the Hot-or-not approach is more work than fun. It's always the same task. Repetition is never fun for humans. Only machines like it.
Let's crunch some numbers: The recaptcha guys claim that "About 60 million CAPTCHAs are solved by humans around the world every day." Say that one of them takes 5 seconds to solve. That amounts to more than 3,400 days of time - and it seems that people regard this time as labor!
What ideas could we think of that make assuring that you're human more fun - like a little 5-second-game?
Here is one: You heard of this place called Web 2.0 where thousands of users generate content and the site creators do nothing but provide the platform?
Why not create a CAPTCHA - platform like this?
Users submit little riddles, you know, obvious ones that you can solve really quick. Just a little picture and a one-word solution to it.
Here, I made a quick example (using Incscape):
I know, it's not beautiful and not funny. But it's different. Everyone will submit different riddles. That's what humans like: "Gee, I wonder what kind of riddle I get this time!".
The fun part here is that they all come from different sources. Each one is different: some are funny, some have a message, others are beautiful ... you get it.
Let's assume it would work in the Web 2.0 manner and thousands or millions of riddle - CAPTCHAs come together, new ones all the time. They would be very, veheery hard to crack using machines. The spammers would have a hard time defining the problem space. They just wouldn't know what to adjust their algorithms to.
I hear you say that people would never submit riddles to a platform in satisfying numbers - but that is the same argument they brought forward when Wikipedia and YouTube started.
So, the riddle CAPTCHA platform already has some Web 2.0 features like user-created (and user-owned) content. We don't need to add social networking, but let's add the Architecture Of Participation:
Riddles could be ranked. Each commentor is asked how (s)he liked the riddle (this requires just one click and is not mandatory). This would create the popularity contest that Web 2.0 people like so much. However, the popularity of a riddle would not be reflected in the number of times it gets used. That would be too easy for the spammers.
Alright, that's how far I'm pushing this idea forward for now.
If anyone has objections why this is a bad idea, please comment.
06 Jun 2007
A real Cognitive Science souvenir is a photo of yourself while participating in an EEG study. I just did my second one, which had me looking at animal pictures, listening to animal sounds and hitting a button when the right animal appeared.
Here are my souvenirs:


Here are my souvenirs:


12 Apr 2007
I just watched the Google tech Talk about the new Yahoo Pipes Service.
It's very cool (I also liked to hear about difficulties when using the Javascript Canvas feature).
Basically, you can combine RSS feeds (which is a standardized XML format) from different web pages and do stuff with them. You may want to filter for keywords. Those keywords may in turn come from another RSS feed. You can generate results for specific problems very quickly.
The working example in the talk is to find apartments on Craigs List whose address are in Palo Alto, California within a range of 1 mile to a park.
Here is another example showing off their great in-browser editor.

A great idea.
I kept on thinking for two minutes and had the idea that you might make this usable without this editor you see above. You see, they made it so good you can almost read out loud what is happening in the pipe.
It should be possible to translate Natural Language, or a subset of it, to a Yahoo Pipe. How great would that be? Ok, a subset of Natural Language to describe queries... hey, that's SQL!
Then I googled for "yahoo pipes sql" and found out I wasn't the first with that idea. Of course not. It's a great point and I'm not ashamed to emphasize it again.
It's very cool (I also liked to hear about difficulties when using the Javascript Canvas feature).
Basically, you can combine RSS feeds (which is a standardized XML format) from different web pages and do stuff with them. You may want to filter for keywords. Those keywords may in turn come from another RSS feed. You can generate results for specific problems very quickly.
The working example in the talk is to find apartments on Craigs List whose address are in Palo Alto, California within a range of 1 mile to a park.
Here is another example showing off their great in-browser editor.
A great idea.
I kept on thinking for two minutes and had the idea that you might make this usable without this editor you see above. You see, they made it so good you can almost read out loud what is happening in the pipe.
It should be possible to translate Natural Language, or a subset of it, to a Yahoo Pipe. How great would that be? Ok, a subset of Natural Language to describe queries... hey, that's SQL!
Then I googled for "yahoo pipes sql" and found out I wasn't the first with that idea. Of course not. It's a great point and I'm not ashamed to emphasize it again.
10 Apr 2007
It happens to me once in a while that I get the feeling to be overwhelmed by the complexity of all the electronic stuff I am working with.

Programs that I use as tools, libraries that I use to write code and the source code I write myself. They interplay. They may work or they don't. It may be my fault or not.
And there are those thousands or maybe millions of tools and libraries out there that I could use but haven't heard of. Maybe I would find the perfect solution within the next click on Google? Where is it?
This article by the creator of one of my favorite leisure time surf sites brings another issue to the point: Software projects, ours included, fail way more often than we like to admit. OK, we felt that this true. Building nice, reliable software is hard. It's somehow an unsolved problem.
But here is the punchline: You can call a project successful when it lasts 15 years.
15 years. Somehow I knew about this, but I never consciously thought about it. It's true. Today, especially in information technology (but not exclusively), putting something out there that lasts for 15 years is almost all you can hope for.
It happens if you're really good.
In five years, there will be new ways of doing things and your project will be considered old. They'll probably think your code has that old-man-odor and it takes another two years until someone finally rewrites it, but that will be it, mostly.
 It's stuff to make you throw the keyboard away and run away to start a new happy life in the forests.
It's stuff to make you throw the keyboard away and run away to start a new happy life in the forests.
With software, it feels like the effort needed to be put into the work to make it last a few years is ridiculously high.
But then again, maybe we can take joy in this modern craftsmenship again by accepting that it's faster, but it's not so different. I love this story from David Humphrey, who swims through the ocean of Open Source software trying to make sense of it. He learned about his grandfather and found out how much the things they do/did are/were alike, even with 50 years difference:
[ed: Like him,] I take things that were never meant to go together and work with them until they fit, patiently refusing to give up - even when it’s not clear I can make it work. Where she and my grandfather worked with pump motors, I work with source code.
Maybe not even the success rate changes so dramatically. As more programs get written (aka. as more tools are made), there is more success and more failure, both of those numbers go up.
What changes is the time frame. It's faster.
And also the standards rise. Less people feel they need to keep that ol' piece of software when there is so much innovation out there.
It's the way of the world.
However, maybe we are telling our kids the same stuff again one day: "When I was young, you could fix or build most of the software yourself. Today, it seems impossible!! *cough*"
26 Mar 2007
I was browsing through my Google Page statistics lately. Gosh, I didn't know I would be found primarily for terms like that. But let's begin from the start.
I include some Java Script code on my page. This code informs Google about visitors on my page. That way, Google is able to tell me how many people came to my site. Or where they came from. And sometimes what they were doing before.
You see, when you search for something at Google or any other search engine, you visit an URL like this:
http://www.google.com/search?q=fluch%20der%20kindheit&hl=en
The search query is right in there. Here, it's "fluch der kindheit" (german for "curse of childhood"). Hold on to that, it's gonna be important.
When someone clicks on a link that was presented as a result for that search, the server that hosts this page will know which was the last URL you visited before (it's called "last referrer" or something like that). This way, Google knows where my visitors came from.
Now, Google can tell me for which search queries my page was listed at good positions, say in one of the top ten.
It turns out that when people, for whatever reason, google for "fluch der kindheit", my page turns up at number four, or near there. Yippie.

Guys, my childhood wasn't that bad. I was only joking there. I have to study harder so one day I will program a sense of irony into Google :-)
I include some Java Script code on my page. This code informs Google about visitors on my page. That way, Google is able to tell me how many people came to my site. Or where they came from. And sometimes what they were doing before.
You see, when you search for something at Google or any other search engine, you visit an URL like this:
http://www.google.com/search?q=fluch%20der%20kindheit&hl=en
The search query is right in there. Here, it's "fluch der kindheit" (german for "curse of childhood"). Hold on to that, it's gonna be important.
When someone clicks on a link that was presented as a result for that search, the server that hosts this page will know which was the last URL you visited before (it's called "last referrer" or something like that). This way, Google knows where my visitors came from.
Now, Google can tell me for which search queries my page was listed at good positions, say in one of the top ten.
It turns out that when people, for whatever reason, google for "fluch der kindheit", my page turns up at number four, or near there. Yippie.
Guys, my childhood wasn't that bad. I was only joking there. I have to study harder so one day I will program a sense of irony into Google :-)
28 Feb 2007
Since almost two months, I spend a lot of time in the Institute for Neurobiopsychology at my local university, programming a tool that helps researchers create models of human attention.
I'll explain that tool some other day, but it's very exciting and almost finished.
Today, I thought I'd share what this place looks like.
It's here:
This is where I sit:

Find more pictures of that ugly building here. The beauty is not in the surrounding, but in the work I do .-)
I'll explain that tool some other day, but it's very exciting and almost finished.
Today, I thought I'd share what this place looks like.
It's here:
This is where I sit:
Find more pictures of that ugly building here. The beauty is not in the surrounding, but in the work I do .-)
07 Jan 2007
The resolution of the images Google uses for its Maps and the famous Google Earth are getting better all the time.
Boston is the city where the pictures are the best. At xrez.com there is a big zoomable picture of Boston, and this little part of it shows just how fine the resolution is these days:

Boston is the city where the pictures are the best. At xrez.com there is a big zoomable picture of Boston, and this little part of it shows just how fine the resolution is these days:
21 Dec 2006
At the moment, in my attempt at Interactive Storytelling, I'm thinking about storyworlds. Worlds, in which stories can be told.
My topic of interest is now language.

(Wait,wait,I'll explain the picture later)
Language, normal written language, is the only real material I am working with.
It is the mind and the matter.
In advanced applications, you also want other types of language, like body language or facial expressions. They will make experience complete. But basically, they don't carry the meaning. You can read a book and use your imagination to enrich the meaning with experience that way.
Written language, therefore, is not a problem that I'll handle at the beginning and then can go do other interesting stuff. I will deal with it all the time.
As will become clear later in this text, every single time I think of what the system can or should do, I will return to the language to make it sayable. So, in a way, such a system has some kind of Sapir-Worf hypothesis as inbuilt premise (that's a famous and much disputed linguistic hypothesis saying that you can't think what you can't say).
The point here, and that is what makes this task so interesting to me, is not to come up with a system that can communicate about anything in any style. I now about the infinity and complexity of language. It is out of my respect that I know that the best thing I can do now is a great illusion. My success is measured by the difference between the effort I put in and the experience I actually accomplish.
In a way, you can compare Interactive Storytelling at the current stage to the movies a hundred years ago. The technology was only evolving, but you could come up with ingenuous methods to create an illusion that really entertained people.
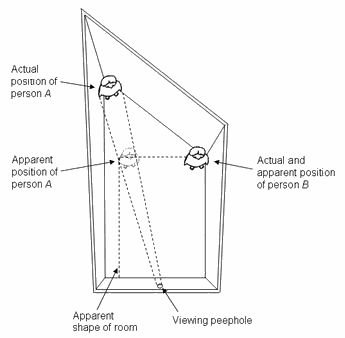
For instance, the "Ames-Room" trick to make one person seem ridiculously small compared to others, like Jim Carry in "Eternal sunset of the spotless mind" when he goes through his childhood again in his dreams. In the bonus material on the DVD they explain how they did it. They were not using computer effects, they were doing it the old-fashioned way.
The way the innovators of cinema did it 100 years ago. They build a room that changed perspective by narrowing walls. If you see it from one perspective, people that are standing 10 meters apart actually seem to be next to each other. But of course they are seen in different sizes. This trick is old, but still used.
Maybe some tricks that are invented for Interactive Storytelling these days will still be used 50 years from now.
Ok, back to our actual technical problem: language. Language makes it possible to say anything. We don't want that.
In fact, the truth is, we can't handle that. Because every sentence must be transferred to mean something.
When the user wants to say:
"I kick Fred"*
we must have a Fred represented in our system and calculate his hurt he experienced by the kicking. Earlier, we would have to know that "shoot" is a verb and it goes with one transitive object.
Or maybe we said it can have two:
"I kick Fred in the butt"
So now the first transitive object declares who we kick, and the second declares where we kick him/her.
So that's introducing the structure problem. That's what grammars are for. The trouble is only just beginning.
Can we only kick people? I could kick a dog, too. Or a vase. Do I need an ontology of things in the world, so that I can kick anything that's build of matter? That relates to the problem called "semantics".
Now to the really hard stuff: Meaning. If I kick the vase, what does it mean to Fred? Is it his vase? Does he like it and should now be sad? Am I showing aggressive behavior and he should be fearful? Or are we drunk teenagers and it actually doesn't mean anything but fun (and a little danger of getting caught)?
That's a hell lot of stuff to chew on. Some might say that more computer power and advances in language processing technology that rely on statistical methods on large natural language corpora will someday overcome those problems. Ok, some things will change. Translation, for instance, is on the edge to become really good within a few years. But at least the meaning problem is different. No brute force will solve it.
This is were some really smart engineering should do dome magic. Not to solve it, mind you, but to allow building applications that give you the feeling that they can hadle what you intend to say about the world it deals with.
The trick that I'm after here, that might enable me one day to deliver an illusion that people will bother spending their time with, will have something to do with the creation of a sublanguage.
A sublanguage that allows me to keep control of everything that needs to be done to turn utterances into things happening in the world. To compute reactions. At the same time, using the sublanguage shouldn't make the user feel restricted.
Within the huge space of possibilities that language offers, I need to carve a room that's handy to work in, but also comfortable to live in.
Some rooms can made to seem larger than they are, like they do it in the movies. Sadly, I can not force the user into one and only one viewing position.
* using the name "Fred" is a reminiscence to Chris Crawford's great book "On Interactive Storytelling". He uses this name for examples a lot.
20 Nov 2006
I think this picture tells it all - many of us feel just like that too much of the time.

There is a brilliant talk by Professor Schwartz on this topic called "Less is more".
There is a brilliant talk by Professor Schwartz on this topic called "Less is more".
11 Nov 2006
I'm certainly no expert in videogaming. But since I read around the topic a bit in the last weeks, I am following the events as a bystander. The video game market has a lot of money to offer - and a lot of money is spent there. The big players are Sony (Playstation), Microsoft(XBox) and Nintendo(Wii).
Many discuss what the future properties of gaming will be: Games might surpass movies in the number one blockbuster entertainment category. Or: Games will be used for education.
 Today, the new Playstation 3 was released in Japan. In a few days, Nintendo will release its next generation console, the Wii.
Today, the new Playstation 3 was released in Japan. In a few days, Nintendo will release its next generation console, the Wii.
The interesting thing for me is: Will they be successful? Some people (eloquently) suggest that those big players have been building up a bubble which will crash soon. They are investing a lot of money, but the novelties in the last year haven't been extraordinary.
But what is about overall sales in the long run? Compare the sales figures to the actual investments made (many say that Microsoft is already losing lots of dollars). Will players actually be frustrated?
I do hope so, because that's when it gets interesting :-)
Update Nov 13:
It seems that with the PS3, Sony will lose several billion dollars, too. I would say that it's ok to lose some money with a ground-breaking product, so you can earn it later with the market share the product brought you. But 5 billion dollars (or whatever it really will be) is not "some", not even for Sony, and as I said above, I don't see this product leading anywhere that spells "innovation of user experience". It's just a bunch of high-tech features thrown against the wall, hoping that some of them will stick with the user.
This market is indeed showing classical signs of a bubble. The critical measure will be the willingness of people to pay for these "innovations".
Many discuss what the future properties of gaming will be: Games might surpass movies in the number one blockbuster entertainment category. Or: Games will be used for education.
Today, the new Playstation 3 was released in Japan. In a few days, Nintendo will release its next generation console, the Wii.The interesting thing for me is: Will they be successful? Some people (eloquently) suggest that those big players have been building up a bubble which will crash soon. They are investing a lot of money, but the novelties in the last year haven't been extraordinary.
- There are advances in graphic capabilities, but they have gotten slower. It's not the same Aha-moment we had 6 years ago. Why pay hundreds of dollars?
- The advances in technical capabilities mostly include added functionalities that have nothing to do with gaming: Playing music, a web browser and so on. I don't think that those capabilities are really able to impress a lot of people that have real computers at home. In addition, those features will all be pretty proprietary. I see a lot of frustration on the horizon.
- The most important point: There is no innovation in ideas for games. In the end, almost all of them are mere finger training. They don't capture your imagination. Microsoft hired Peter Jackson to bring stories to games, but one attempt might not be enough. Maybe the industry needs a crash, so that bottom-up innovation can make its path (And of course this is where I see interesting opportunities for developers to get heard).
But what is about overall sales in the long run? Compare the sales figures to the actual investments made (many say that Microsoft is already losing lots of dollars). Will players actually be frustrated?
I do hope so, because that's when it gets interesting :-)
Update Nov 13:
It seems that with the PS3, Sony will lose several billion dollars, too. I would say that it's ok to lose some money with a ground-breaking product, so you can earn it later with the market share the product brought you. But 5 billion dollars (or whatever it really will be) is not "some", not even for Sony, and as I said above, I don't see this product leading anywhere that spells "innovation of user experience". It's just a bunch of high-tech features thrown against the wall, hoping that some of them will stick with the user.
This market is indeed showing classical signs of a bubble. The critical measure will be the willingness of people to pay for these "innovations".
10 Nov 2006
My first job for an own approach to interactive Storytelling was a prototype for the User Interface. Chris Crawford suggested to use an inverse parser, and I liked the idea. A parser is a program that can tell if a sentence is valid for a given grammar. An inverse parser takes a part of a sentence and tells you what would be a valid way to go from there to build a valid sentence. That is of course a nice way to help users input sentences to a program that uses a grammar. My own picture of how to deliver that idea is that I plan to deliver the "game" over a web browser.
Here is a screenshot of the first prototype, using only a very simple language with very few words. But I think you get the idea.
On the left you see the menu with which you construct what you want to say or do. On the right is just a list of things you said or did.
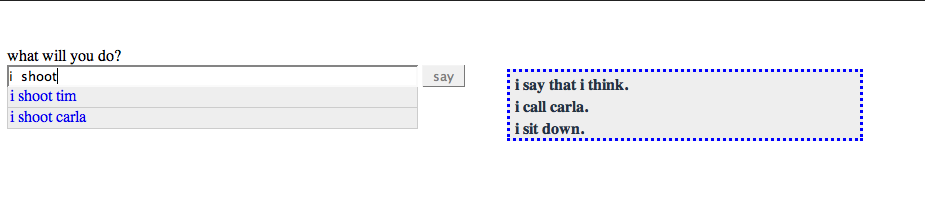
The parser proposes optional next words as you type. You can also avoid typing and only select from the dropdown menu by using the mouse or cursor buttons.
If a complete sentence was entered, the input box turns green and the "say" button is activated. If you enter a letter so that your sentence will never be valid, the input box turns red.
Some technical details:
I'm learning to love Python as my favorite Programming Language. In addition, I thought that Prolog would be a great language to code the grammar in. I struggled hard to get Python, running on an Apache Webserver, to use Prolog via Pylog, an interface plugin between the two. It was too hard once I tried using it over the webserver. There are several independent processes talking to each other, one of them being the Apache Webserver, and it's much trouble.
I decided to write the whole parser myself, using Python and its Generator idea - for now, it works great.
The interaction with the parser on the way is using Ajax technology to create the auto-suggest-box (thanks to brandspankingnew for inspiration). I'll need to see how well that works with a big grammar, but the communication load will never be too big (I'll introduce a limit to the amount of suggestions that are send at once).
Here is a screenshot of the first prototype, using only a very simple language with very few words. But I think you get the idea.
On the left you see the menu with which you construct what you want to say or do. On the right is just a list of things you said or did.
The parser proposes optional next words as you type. You can also avoid typing and only select from the dropdown menu by using the mouse or cursor buttons.
If a complete sentence was entered, the input box turns green and the "say" button is activated. If you enter a letter so that your sentence will never be valid, the input box turns red.
Some technical details:
I'm learning to love Python as my favorite Programming Language. In addition, I thought that Prolog would be a great language to code the grammar in. I struggled hard to get Python, running on an Apache Webserver, to use Prolog via Pylog, an interface plugin between the two. It was too hard once I tried using it over the webserver. There are several independent processes talking to each other, one of them being the Apache Webserver, and it's much trouble.
I decided to write the whole parser myself, using Python and its Generator idea - for now, it works great.
The interaction with the parser on the way is using Ajax technology to create the auto-suggest-box (thanks to brandspankingnew for inspiration). I'll need to see how well that works with a big grammar, but the communication load will never be too big (I'll introduce a limit to the amount of suggestions that are send at once).
25 Oct 2006
Here is a short list of ressources to that interesting new world of Interactive Storytelling:
Wikipedia on Interactive Storytelling
The article is really short, it becomes interesting when compared to Interactive Fiction.
The Website of Chris Crawford's new company (founded this year). It's a mixed team of under 10 people. They want to commerzialize Crawford's Erasmatron engine. Part of the plan is to attract creative writers that would use their tool to create storyworlds. The actual beta version of their development tool is not very intuitive at this point (see below), but no one said it's gonna be easy (and I admit I didn't read the tutorial).
The blog of the creators of Facade and others (Facade is one of the first serious approaches in Interactive Storytelling - well, Interactive Drama... You should try it out. It only takes 10 minutes or so. They, too, are working on a new product (but calculate with 3 years - there is much work in such a thing...)
Wikipedia on Interactive Storytelling
The article is really short, it becomes interesting when compared to Interactive Fiction.
The Website of Chris Crawford's new company (founded this year). It's a mixed team of under 10 people. They want to commerzialize Crawford's Erasmatron engine. Part of the plan is to attract creative writers that would use their tool to create storyworlds. The actual beta version of their development tool is not very intuitive at this point (see below), but no one said it's gonna be easy (and I admit I didn't read the tutorial).
The blog of the creators of Facade and others (Facade is one of the first serious approaches in Interactive Storytelling - well, Interactive Drama... You should try it out. It only takes 10 minutes or so. They, too, are working on a new product (but calculate with 3 years - there is much work in such a thing...)
04 Oct 2006
When I visited Gambia (that's on the western coast of Africa), I thought about the Digital Divide and what could be done to help people there to catch up on getting in touch with computers, a bit at least.
I realized that that would achieve the best results when you target children, as they are eager to learn and have no fear of things that are completely new.
 My first idea was to offer godparenthoods, meaning you would guarantee daily or weekly internet access for one or more children in Africa for a small amount opf money (the concept is borrowed from the godparenthood programmes where you ensure education in a school or food. However, this concept would target another kind of donours, namely geeks).
My first idea was to offer godparenthoods, meaning you would guarantee daily or weekly internet access for one or more children in Africa for a small amount opf money (the concept is borrowed from the godparenthood programmes where you ensure education in a school or food. However, this concept would target another kind of donours, namely geeks).
My thougths about that were mostly concerned with money, organizational problems, infrastructure and so on.
I rememered those thoughts when I read this article, concerned with a closer look at what the children would actually do on the internet. Or, how they would approach the computer in general.
It deals with the idea of an indian computer scientist. He put a computer in the wall next to a street where slum kids played. Then, without any explanations or guidelines he just watched what happened as the children discovered that strange device. They teached themselves really stunning things on the computer and explored the web within a few weeks. You should really read the article/interview. It's not that long, either.
I only have two concerns:
I realized that that would achieve the best results when you target children, as they are eager to learn and have no fear of things that are completely new.
My first idea was to offer godparenthoods, meaning you would guarantee daily or weekly internet access for one or more children in Africa for a small amount opf money (the concept is borrowed from the godparenthood programmes where you ensure education in a school or food. However, this concept would target another kind of donours, namely geeks).My thougths about that were mostly concerned with money, organizational problems, infrastructure and so on.
I rememered those thoughts when I read this article, concerned with a closer look at what the children would actually do on the internet. Or, how they would approach the computer in general.
It deals with the idea of an indian computer scientist. He put a computer in the wall next to a street where slum kids played. Then, without any explanations or guidelines he just watched what happened as the children discovered that strange device. They teached themselves really stunning things on the computer and explored the web within a few weeks. You should really read the article/interview. It's not that long, either.
I only have two concerns:
- One thing that I also thought about back in Africa is what happens when you open these children to email or instant messaging. There are certainly bad experiences to be made out there. Children in western countries are endangered by pedophiles or other threads, too, but they are better informed as they grow up with the technology and, most important, they are rich and thus far less easy to be tempted.
- Mitra (the indian scientist) compares those self-educated children to indian cable technicians. Most of those people can do a good job without any deeper understanding of the system they're dealing with. They just remember sequences of actions that lead to successs. Maybe that's a necessary intermediate step to a knowledge society. But maybe it's inherent to indian culture. The latter option would be a really bad sign for India...
25 Sep 2006
I always suspected that nerds are cool. Here is the video proving it:
(and another version, pictures from someone else, but with lyrics to it).
But dont't panic: I made the test to the song, and ...

(and another version, pictures from someone else, but with lyrics to it).
But dont't panic: I made the test to the song, and ...
16 Aug 2006
 For her last birthday, I buyed an old G3 iMac for my girlfriend. I planned to upgrade it with RAM and a bigger harddrive.
For her last birthday, I buyed an old G3 iMac for my girlfriend. I planned to upgrade it with RAM and a bigger harddrive. Long story short, I did it, but it was a hell lot of work and unexpected problems. And maybe I even would have messed something up badly, if I didn't find this excellent website. Some guy explains every little step in upgrading an old iMac in detail. And just for the model I bought on eBay. There are a lot of models out there, but his page only deals with the one I bought! With pictures of each step even!
How crazy is that guy?
Well, it seems that a lot of people are that crazy. Nobody predicted the bottom-up content revolution of the internet before it was born. There seems to be altruism everywhere and all it took to unleash it was to give people tools to do it: HTML and a network.
But there is another interesting, related phenomena that these days few people, at least few non-it-technical people, know about: People also build software and share it for free. Nothing. Nada.
It's called Open Source. For instance, this pages are hosted on a server that runs on Apache, which is a great, complex software, and totally free. It generates income for my Webhoster, so there are a lot of interesting economic implications there, which I haven't found the time to think over really.
My point is, there has been more and more free software made available in the last few years. Heck, even this PolyPager tool I wrote to make my webpages is free for everybody, and it uses free tools itself.
I realized this once more in the project I am currently involved in at the University of Osnabrück. We're a small team of students with no budget creating a quite powerful software for scientific experiments. We're using so many great software tools that I can't even list all the great stuff these tools are doing for us.
Here is a short list of the tools themselves (in no specific order - almost all of those have been developed in the spare time of thousands of smart people, the others are developed by companies for public use):
I think that most people haven't understood how great this is: These tools are really powerful. You can start a whole company with tools that cost you nothing. All you need is your head (and a computer, and internet and so on, admitted, but you get the point). This has not been true 15 years ago. It has been true 10 years ago, but almost exclusively for web applications. Now there is free software for almost anything. For a quickly-googled example: I am no expert in Computer-Aided Design (CAD), but I know it's an engineering method used in industrial development and it requires complex and expensive software. Well, here is a software that does it for free (notice the pictures that show what you might design with that software).
Now, you might argue over the motives that lead to so much sharing of worth. You might say that much of it isn't altruistic at all, but showing off skills or trying to lead the pack by defining the standard software. Agreed. There are many motives.
But I think there are a lot implications that we're not thinking about enough. What does this mean for progress? For ecomomic growth? For globalization? (For instance: Do we share to much knowledge with, for example, China?) For culture? (What does a copyright imply? What licence models should we have?) For patents?
Etcetera.
There are some people debating all this, but considering the implications Open Source has on the economy (already and in 10 years), there is far too less debate.
19 Jun 2006
I am currently working as a tutor in the course "Introduction to Artificial Intelligence". That sounds great, but half of the work is really only correcting Prolog-homeworks and help guarding the exams.
The other half, however, is holding a tutorial once a week, showing slides and all that. This is done so that everyone who didn't understand the professor or doesn't know how to start with the homework can get advice from a student that roughly knows why understanding this might be hard.
Besides teaching me to speak english in front of people, this helps me learn to create content for people. Over the semester, I learned that I get more attention if I look carefully what those students need right now. That's actually a good lesson nowadays because in the web attention is measured by traffic and/or clicks and that measurability makes it easy to translate attention into success.
Ok, now how do I measure that attention?
I picked a bad date for my tutorials: friday afternoon. Of course most of the students will be home or already in their weekend, so there are just a handful people showing up each friday. But thanks to our university's online information system, tutors (as well as professors of course) can upload their presentation slides where students can look at them whenever and whereever they want. The system also counts downloads, too. As this screenshot of the download area (click it) shows, I can see that this audience is much more attentive than the physical audience on friday afternoon is:
I can also see where I tried to be sharp and give the students too much of my precious skills. With the third session, I was down to a little more than 30 downloads. After that, I talked about topics that were less advanced and more homework-centered. You don't see that too much in the title, but in the content (some of them are available here in the takeaway-section).
The other half, however, is holding a tutorial once a week, showing slides and all that. This is done so that everyone who didn't understand the professor or doesn't know how to start with the homework can get advice from a student that roughly knows why understanding this might be hard.
Besides teaching me to speak english in front of people, this helps me learn to create content for people. Over the semester, I learned that I get more attention if I look carefully what those students need right now. That's actually a good lesson nowadays because in the web attention is measured by traffic and/or clicks and that measurability makes it easy to translate attention into success.
Ok, now how do I measure that attention?
I picked a bad date for my tutorials: friday afternoon. Of course most of the students will be home or already in their weekend, so there are just a handful people showing up each friday. But thanks to our university's online information system, tutors (as well as professors of course) can upload their presentation slides where students can look at them whenever and whereever they want. The system also counts downloads, too. As this screenshot of the download area (click it) shows, I can see that this audience is much more attentive than the physical audience on friday afternoon is:
I can also see where I tried to be sharp and give the students too much of my precious skills. With the third session, I was down to a little more than 30 downloads. After that, I talked about topics that were less advanced and more homework-centered. You don't see that too much in the title, but in the content (some of them are available here in the takeaway-section).
08 Jun 2006
Well, I know how to see the error page. Search for osx "operating system". I tried it three times and always get this error page:

Other terms with the same structure (for example) bla "bla bla" work. Nice bug, indeed...
Update that same afternoon: The error doesn't appear no more. Would be interesting to know what happened there... At least I now know that they use Perl. Oh god, I'm such a geek!
Other terms with the same structure (for example) bla "bla bla" work. Nice bug, indeed...
Update that same afternoon: The error doesn't appear no more. Would be interesting to know what happened there... At least I now know that they use Perl. Oh god, I'm such a geek!
29 May 2006
aharef.info has an applet to make website structure viewable. The pictures resemble organic structures in a beautiful way, and good, modern structural design becomes clear at a glance. Here is my page:
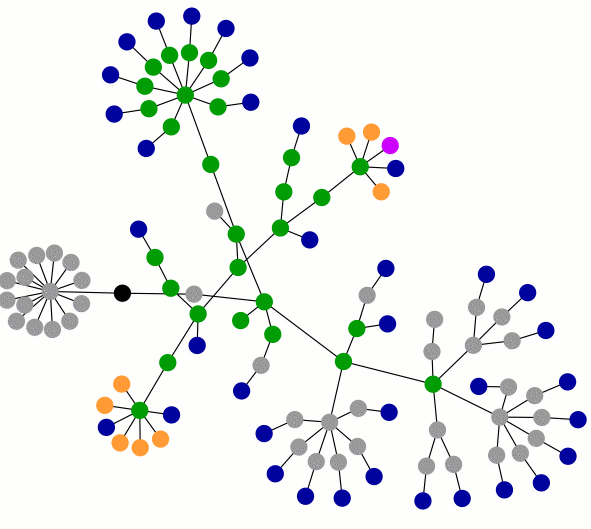

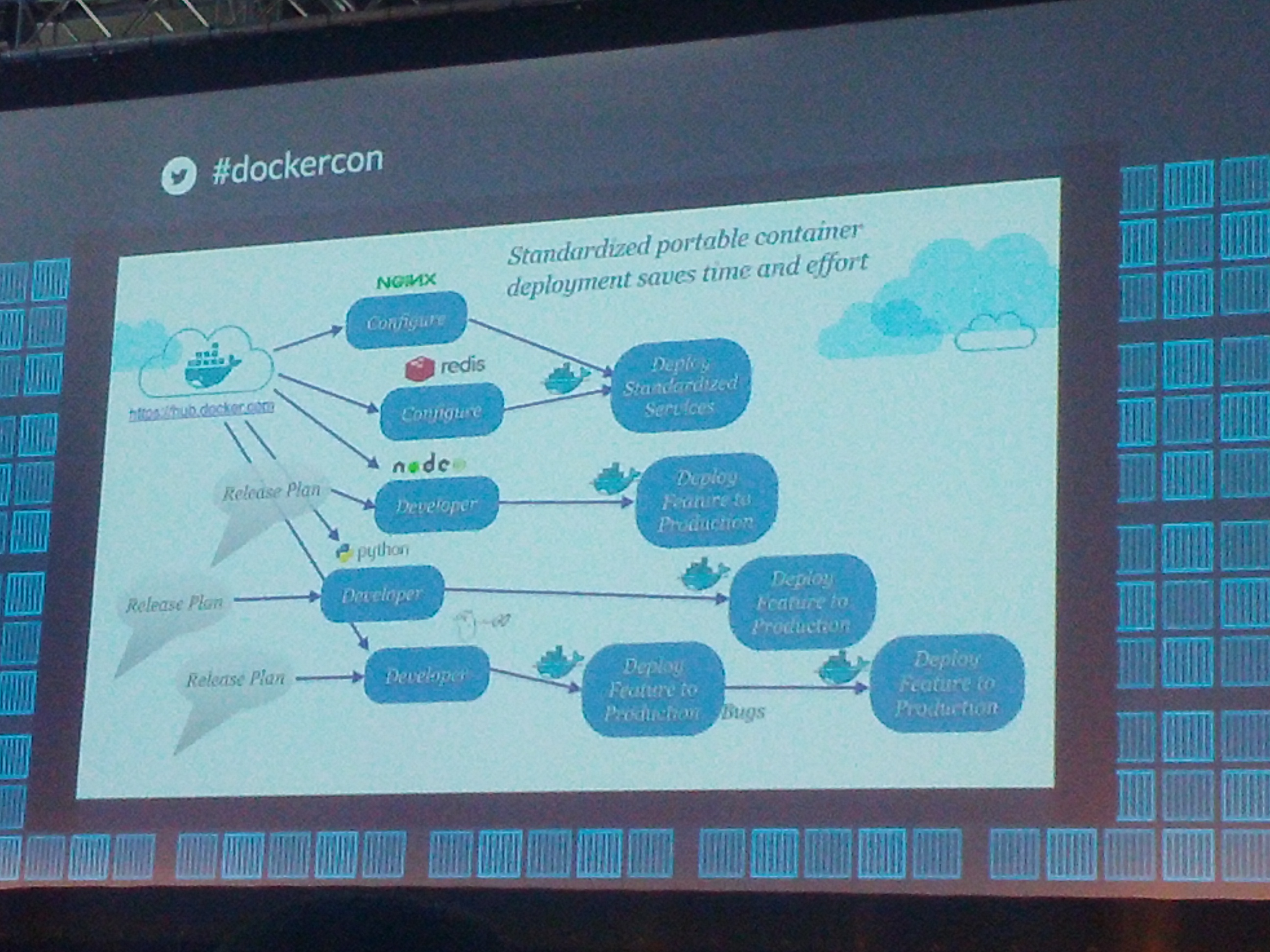{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
22 Sep 2005
When I tried out Ubuntu a few weeks ago, I stumbled over the option to order the original Ubuntu CDs.
I am now happily running Ubuntu since then. And today, the postman rang. I didn't think about the CDs anymore, so I sure was surprised to find this :
I ordered so much, because they said on their website that they don't care how much I'd take. I was near the minimum they had suggested :-) Red is for Intel x86, yellow for the new AMD64/EMD64T processors and orange for Power PCs (Mac).
Each CD has an install and a live CD. Good work!
I am now happily running Ubuntu since then. And today, the postman rang. I didn't think about the CDs anymore, so I sure was surprised to find this :
I ordered so much, because they said on their website that they don't care how much I'd take. I was near the minimum they had suggested :-) Red is for Intel x86, yellow for the new AMD64/EMD64T processors and orange for Power PCs (Mac).
Each CD has an install and a live CD. Good work!